

Very interesting indeed. Way to do the right thing here Verizon. This may be the first time I've been happy to be a Comcast customer. -- Josh Smith kD8HRX email/jabber: juicewvu@gmail.com Phone: 304.237.9369(c) Sent from my iPad On Apr 6, 2013, at 9:24 PM, "cb.list6" <cb.list6@gmail.com> wrote:
Interesting.
http://www22.verizon.com/support/residential/internet/highspeedinternet/netw...

Good to see that they are providing a way for users to opt out. I'm hoping that other ISP's will do the same when they implement CGN. Oliver ------------------------------------- Oliver Garraux Check out my blog: blog.garraux.net Follow me on Twitter: twitter.com/olivergarraux On Sat, Apr 6, 2013 at 9:32 PM, Joshua Smith <juicewvu@gmail.com> wrote:
Very interesting indeed. Way to do the right thing here Verizon. This may be the first time I've been happy to be a Comcast customer.
-- Josh Smith kD8HRX
email/jabber: juicewvu@gmail.com Phone: 304.237.9369(c)
Sent from my iPad
On Apr 6, 2013, at 9:24 PM, "cb.list6" <cb.list6@gmail.com> wrote:
Interesting.
http://www22.verizon.com/support/residential/internet/highspeedinternet/netw...

It would be nice to get an update from them regarding their IPv6 plans. Their IPv6 support page still says they will start deploying "3Q12" :(. On 4/6/2013 9:32 PM, Joshua Smith wrote:
Very interesting indeed. Way to do the right thing here Verizon. This may be the first time I've been happy to be a Comcast customer.


I think Comcast is using CGN too!!! My IP address displayed on my MacBook is in the 10.0.0.0/8 range, and ARIN website can't determine my IP address either. Joe Sent from my iPhone On Apr 6, 2013, at 9:33 PM, "Joshua Smith" <juicewvu@gmail.com> wrote:
Very interesting indeed. Way to do the right thing here Verizon. This may be the first time I've been happy to be a Comcast customer.
-- Josh Smith kD8HRX
email/jabber: juicewvu@gmail.com Phone: 304.237.9369(c)
Sent from my iPad
On Apr 6, 2013, at 9:24 PM, "cb.list6" <cb.list6@gmail.com> wrote:
Interesting.
http://www22.verizon.com/support/residential/internet/highspeedinternet/netw...

I think Comcast is using CGN too!!! My IP address displayed on my MacBook is in the 10.0.0.0/8 range, and ARIN website can't determine my IP address either.
Joe
Sent from my iPhone
On Apr 6, 2013, at 9:33 PM, "Joshua Smith" <juicewvu@gmail.com> wrote:
Very interesting indeed. Way to do the right thing here Verizon. This may be the first time I've been happy to be a Comcast customer.
-- Josh Smith kD8HRX
email/jabber: juicewvu@gmail.com Phone: 304.237.9369(c)
Sent from my iPad
On Apr 6, 2013, at 9:24 PM, "cb.list6" <cb.list6@gmail.com> wrote:
Interesting.
http://www22.verizon.com/support/residential/internet/highspeedinternet/netw... if you are a business customer your modem is actually a business grade NAT router. If they are using CGN(which doesn't make sense as i can
On 4/6/2013 11:33 PM, Huasong Zhou wrote: pull an ipv6 addy here on dhcp) it's either a misconfiguration or something else going on.

Nope. Comcast is not using any CGN, as much as I know. Is your MacBook directly connected to the modem or a router? I presume the latter. Cheers, Rajiv Sent from my Phone On Apr 7, 2013, at 11:47 AM, "Huasong Zhou" <huasong@kalorama.com> wrote:
I think Comcast is using CGN too!!! My IP address displayed on my MacBook is in the 10.0.0.0/8 range, and ARIN website can't determine my IP address either.
Joe
Sent from my iPhone
On Apr 6, 2013, at 9:33 PM, "Joshua Smith" <juicewvu@gmail.com> wrote:
Very interesting indeed. Way to do the right thing here Verizon. This may be the first time I've been happy to be a Comcast customer.
-- Josh Smith kD8HRX
email/jabber: juicewvu@gmail.com Phone: 304.237.9369(c)
Sent from my iPad
On Apr 6, 2013, at 9:24 PM, "cb.list6" <cb.list6@gmail.com> wrote:
Interesting.
http://www22.verizon.com/support/residential/internet/highspeedinternet/netw...
We got this modem and router all in one box from Comcast directly. And by the way, home use routers don't assign 10.0.0.0 numbers. Joe Sent from my iPhone On Apr 7, 2013, at 9:11 PM, "Rajiv Asati (rajiva)" <rajiva@cisco.com> wrote:
Nope. Comcast is not using any CGN, as much as I know.
Is your MacBook directly connected to the modem or a router? I presume the latter.
Cheers, Rajiv
Sent from my Phone
On Apr 7, 2013, at 11:47 AM, "Huasong Zhou" <huasong@kalorama.com> wrote:
I think Comcast is using CGN too!!! My IP address displayed on my MacBook is in the 10.0.0.0/8 range, and ARIN website can't determine my IP address either.
Joe
Sent from my iPhone
On Apr 6, 2013, at 9:33 PM, "Joshua Smith" <juicewvu@gmail.com> wrote:
Very interesting indeed. Way to do the right thing here Verizon. This may be the first time I've been happy to be a Comcast customer.
-- Josh Smith kD8HRX
email/jabber: juicewvu@gmail.com Phone: 304.237.9369(c)
Sent from my iPad
On Apr 6, 2013, at 9:24 PM, "cb.list6" <cb.list6@gmail.com> wrote:
Interesting.
http://www22.verizon.com/support/residential/internet/highspeedinternet/netw...

----- Original Message -----
From: "Huasong Zhou" <huasong@kalorama.com>
We got this modem and router all in one box from Comcast directly. And by the way, home use routers don't assign 10.0.0.0 numbers.
I have seen consumer NAT routers assign addresses in all three RFC1918 blocks, though I couldn't cite particular models for you. 10./ is less common than 172./, but not impossible. Cheers, -- jra -- Jay R. Ashworth Baylink jra@baylink.com Designer The Things I Think RFC 2100 Ashworth & Associates http://baylink.pitas.com 2000 Land Rover DII St Petersburg FL USA #natog +1 727 647 1274

On 9-4-2013 1:10, Jay Ashworth wrote:
----- Original Message -----
From: "Huasong Zhou" <huasong@kalorama.com>
We got this modem and router all in one box from Comcast directly. And by the way, home use routers don't assign 10.0.0.0 numbers.
I have seen consumer NAT routers assign addresses in all three RFC1918 blocks, though I couldn't cite particular models for you. 10./ is less common than 172./, but not impossible.
Early Alcatel/Lucent Speedtouch modems assigned 10/8 to the LAN, effectively breaking all VPN networking to our office. No fun to be had in that one. Luckily all these shipped without Wifi and have now all been replaced by Thomson wifi models that use 192.168.[01]/24 Some of the AlliedData Copperjet modems use 172.x Regards, Seth

On Apr 7, 2013, at 18:45 , Huasong Zhou <huasong@kalorama.com> wrote:
We got this modem and router all in one box from Comcast directly. And by the way, home use routers don't assign 10.0.0.0 numbers.
Some do. Owen
Joe
Sent from my iPhone
On Apr 7, 2013, at 9:11 PM, "Rajiv Asati (rajiva)" <rajiva@cisco.com> wrote:
Nope. Comcast is not using any CGN, as much as I know.
Is your MacBook directly connected to the modem or a router? I presume the latter.
Cheers, Rajiv
Sent from my Phone
On Apr 7, 2013, at 11:47 AM, "Huasong Zhou" <huasong@kalorama.com> wrote:
I think Comcast is using CGN too!!! My IP address displayed on my MacBook is in the 10.0.0.0/8 range, and ARIN website can't determine my IP address either.
Joe
Sent from my iPhone
On Apr 6, 2013, at 9:33 PM, "Joshua Smith" <juicewvu@gmail.com> wrote:
Very interesting indeed. Way to do the right thing here Verizon. This may be the first time I've been happy to be a Comcast customer.
-- Josh Smith kD8HRX
email/jabber: juicewvu@gmail.com Phone: 304.237.9369(c)
Sent from my iPad
On Apr 6, 2013, at 9:24 PM, "cb.list6" <cb.list6@gmail.com> wrote:
Interesting.
http://www22.verizon.com/support/residential/internet/highspeedinternet/netw...

On 4/8/13 5:55 PM, Owen DeLong wrote:
On Apr 7, 2013, at 18:45 , Huasong Zhou <huasong@kalorama.com> wrote:
We got this modem and router all in one box from Comcast directly. And by the way, home use routers don't assign 10.0.0.0 numbers.
Some do.
AT&T U-verse used to have 10.0.0.0/8 as an option until a firmware update removed that capability. My bet is on CGN prep work. ~Seth

On 4/8/13 9:23 PM, "Seth Mattinen" <sethm@rollernet.us> wrote:
On 4/8/13 5:55 PM, Owen DeLong wrote:
On Apr 7, 2013, at 18:45 , Huasong Zhou <huasong@kalorama.com> wrote:
We got this modem and router all in one box from Comcast directly. And by the way, home use routers don't assign 10.0.0.0 numbers.
Some do.
AT&T U-verse used to have 10.0.0.0/8 as an option until a firmware update removed that capability. My bet is on CGN prep work.
No, we (Comcast) are not doing CGN prep work. Jason Livingood Comcast

Huasong Zhou <huasong@kalorama.com> writes:
We got this modem and router all in one box from Comcast directly.
OK, so the NAT is taking place in the router you got from Comcast, not in Carrier Grade NAT in Comcast's network. A fine distinction but an important one. The external address of your router is (a) globally unique, and (b) not shared with any other customer.
And by the way, home use routers don't assign 10.0.0.0 numbers.
Who told you that? I offer you as a counterexample (all? maybe just every one I've owned?) the Airports from Apple. Default LAN address is 10.0.1.1. -r
On 4/7/13 9:45 PM, "Huasong Zhou" <huasong@kalorama.com> wrote:
We got this modem and router all in one box from Comcast directly. And by the way, home use routers don't assign 10.0.0.0 numbers.
Sure they can. And I'm sure if you checked the WAN interface of the device it has a public IPv4 address. - Jason

I can confirm CGN has not been deployed for Comcast customers. ========================================= John Jason Brzozowski Comcast Cable m) 609-377-6594 e) mailto:john_brzozowski@cable.comcast.com o) 484-962-0060 w) http://www.comcast6.net ========================================= ________________________________________ From: Rajiv Asati (rajiva) [rajiva@cisco.com] Sent: Sunday, April 07, 2013 21:11 To: Huasong Zhou Cc: Joshua Smith; nanog@nanog.org Subject: Re: Verizon DSL moving to CGN Nope. Comcast is not using any CGN, as much as I know. Is your MacBook directly connected to the modem or a router? I presume the latter. Cheers, Rajiv Sent from my Phone On Apr 7, 2013, at 11:47 AM, "Huasong Zhou" <huasong@kalorama.com> wrote:
I think Comcast is using CGN too!!! My IP address displayed on my MacBook is in the 10.0.0.0/8 range, and ARIN website can't determine my IP address either.
Joe
Sent from my iPhone
On Apr 6, 2013, at 9:33 PM, "Joshua Smith" <juicewvu@gmail.com> wrote:
Very interesting indeed. Way to do the right thing here Verizon. This may be the first time I've been happy to be a Comcast customer.
-- Josh Smith kD8HRX
email/jabber: juicewvu@gmail.com Phone: 304.237.9369(c)
Sent from my iPad
On Apr 6, 2013, at 9:24 PM, "cb.list6" <cb.list6@gmail.com> wrote:
Interesting.
http://www22.verizon.com/support/residential/internet/highspeedinternet/netw...

On 6 April 2013 18:24, cb.list6 <cb.list6@gmail.com> wrote:
Interesting.
http://www22.verizon.com/support/residential/internet/highspeedinternet/netw...
<blockquote>
What is CGN - and How to opt-out The number and types of devices using the Internet have increased dramatically in recent years and, as a result, address space for these devices is being rapidly exhausted. Today’s technology for IP addresses is referred to as IPv4 (Internet Protocol version 4). The IP addresses aligned with IPv4 are expected to be depleted at some point in the near future. The next generation of IP address space is IPv6, which will enable far more addresses to be assigned than IPv4. Unfortunately, most servers and other Internet devices will not be speaking IPv6 for a while, so IPv4 will remain standard for some time to come.
During this transitional period, in select areas for High Speed Internet residential customers, Verizon will be implementing Carrier Grade Network Address Translation (CGN or Carrier Grade NAT). Verizon FiOS and Verizon Business customers are not impacted at this time by the change. This transition will enable Verizon to continue serving customers with IPv4 internet addresses. CGN will not impact the access, reliability, speed, or security of Verizon’s broadband services. However, there are some applications such as online gaming, VPN access, FTP service, surveillance cameras, etc., that may not work when broadband service is provided via a CGN.
For our customers utilizing these types of applications, Verizon provides the ability to "opt out “of CGN. To "opt out" you must:
Be a Residential customer with High Speed Internet Service. There is no need to “opt-out” if you are a FiOS or Business customer. Have already been transitioned to the Carrier Grade Network by Verizon. If you are a Residential High Speed Internet customer and are unable to opt-out, it is likely that you have not yet been transitioned to CGN.
To "opt out" of CGN sign onto your My Verizon account and select "Opt out of Carrier Grade Network".
</blockquote> I like how, according to the document, Verizon must first break your connectivity, prior to you being able to opt-out. :-) Also:
select "Opt out of Carrier Grade Network"
Smart wording. :-) Frankly, I'm surprised to see this news. I thought Verizon had better things to do that plan any kind of upgrades or changes to something that everyone thought they consider dead anyways. C.

On 07/04/13 12:11, Constantine A. Murenin wrote:
On 6 April 2013 18:24, cb.list6 <cb.list6@gmail.com> wrote:
Interesting.
http://www22.verizon.com/support/residential/internet/highspeedinternet/netw...
<blockquote> ...
...CGN will not impact the access, reliability, speed, or security of Verizon’s broadband services. ... ... </blockquote>
Good luck with that, pretty much by definition it has to do all four (albeit at levels that shouldn't be detectable to the end user)
I like how, according to the document, Verizon must first break your connectivity, prior to you being able to opt-out. :-)
If you look at it from their side this makes a lot of sense, helps to ensure that only those who actually get breakage from the CGN opt out, otherwise you'd never know to request it.

On Sun, Apr 7, 2013 at 1:22 AM, Julien Goodwin <nanog@studio442.com.au>wrote:
...CGN will not impact the access, reliability, speed, or security of Verizon’s broadband services. ... ... </blockquote>
Good luck with that, pretty much by definition it has to do all four (albeit at levels that shouldn't be detectable to the end user)
I wonder how much more painful just upgrading the dsl plant to support v6 would be vs deploying the cgn equipment and funneling users through that :(

On Sun, 07 Apr 2013 01:40:09 -0400, Christopher Morrow said:
I wonder how much more painful just upgrading the dsl plant to support v6 would be vs deploying the cgn equipment and funneling users through that :(
The answer depends on whether the person making the decision thinks they'll have left the company before the IPv6 birds come home to roost. ;)

On Sun, 7 Apr 2013, Christopher Morrow wrote:
I wonder how much more painful just upgrading the dsl plant to support v6 would be vs deploying the cgn equipment and funneling users through that :(
IPv6 deployment is not a short term solution to IPv4 address depletion. Would you be less upset if there was IPv6 access and CPE based DS Lite (ie your IPv4 is still CGN:ed, just in a different way)? CGN is here to stay for IPv4. The solution for long term Internet growth is IPv6. -- Mikael Abrahamsson email: swmike@swm.pp.se

CGN is just a solution to save time, it is not a transition mechanism through IPv6 At the end (IPv6 at home) you will need at list : Dual stack or NAT64/ DNS64 My 2 cents On Apr 7, 2013, at 8:42 AM, Mikael Abrahamsson <swmike@swm.pp.se> wrote:
On Sun, 7 Apr 2013, Christopher Morrow wrote:
I wonder how much more painful just upgrading the dsl plant to support v6 would be vs deploying the cgn equipment and funneling users through that :(
IPv6 deployment is not a short term solution to IPv4 address depletion. Would you be less upset if there was IPv6 access and CPE based DS Lite (ie your IPv4 is still CGN:ed, just in a different way)?
CGN is here to stay for IPv4. The solution for long term Internet growth is IPv6.
-- Mikael Abrahamsson email: swmike@swm.pp.se
On Sun, 7 Apr 2013, Fabien Delmotte wrote:
CGN is just a solution to save time, it is not a transition mechanism through IPv6 At the end (IPv6 at home) you will need at list : Dual stack or NAT64/ DNS64
CGN doesn't stop anyone deploying dual stack. NAT64/DNS64 is dead in the water without other mechanisms (464XLAT or alike). My point is that people seem to scoff at CGN. There is nothing stopping anyone putting in CGN for IPv4 (that has to be done to handle IPv4 address exhaustion), then giving dual stack for end users can be done at any time. Face it, we're running out of IPv4 addresses. For basic Internet subscriptions the IPv4 connectivity is going to be behind CGN. IPv6 is a completely different problem that has little bearing on CGN or not for IPv4. DS-Lite is also CGN, it just happens to be done over IPv6 access. MAP is also CGN. I'm ok with people complaining about lack of IPv6 deployment, but I don't understand people complaining about CGN. What's the alternative? -- Mikael Abrahamsson email: swmike@swm.pp.se

* Mikael Abrahamsson
My point is that people seem to scoff at CGN. There is nothing stopping anyone putting in CGN for IPv4 (that has to be done to handle IPv4 address exhaustion), then giving dual stack for end users can be done at any time.
Face it, we're running out of IPv4 addresses. For basic Internet subscriptions the IPv4 connectivity is going to be behind CGN. IPv6 is a completely different problem that has little bearing on CGN or not for IPv4. DS-Lite is also CGN, it just happens to be done over IPv6 access. MAP is also CGN.
I'm ok with people complaining about lack of IPv6 deployment, but I don't understand people complaining about CGN. What's the alternative?
Technically I agree with all of the above. However, going for the NAT444 flavour of CGN might well delay or lower the perceived importance of IPv6 deployment within an ISP. The immediate problem is IPv4 service continuity, and if that is to be accomplished without IPv6 being part of it, it's easy to postpone doing anything about IPv6. I went to an interesting presentation from Kabel Deutschland last month, who have deployed DS-Lite to their residential subscribers. One of the messages was that once the decision was made to implement DS-Lite to deal with IPv4 exhaustion, there was no problem getting the necessary support to deploy IPv6 - it was no longer a separate and non-revenue-generating problem, but an essential building block needed for their IPv4 service continuity. (MAP and 464XLAT would yield the same effect, of course.) To answer your earlier question - yes, I'd very much prefer to have DS-Lite over NAT444, because only the former will ensure that I get native IPv6 once my native IPv4 gets taken away. With NAT444, I'm no closer to having IPv6 than I was before NAT444. That said, there are of course some things that may make anything except NAT444 undeployable. Verizon might have old DSLAMs that cannot deal with IPv6, or customer-controlled/owned (layer-3) HGWs. If so, their hands are tied. -- Tore Anderson
On Apr 7, 2013, at 00:31 , Mikael Abrahamsson <swmike@swm.pp.se> wrote:
On Sun, 7 Apr 2013, Fabien Delmotte wrote:
CGN is just a solution to save time, it is not a transition mechanism through IPv6 At the end (IPv6 at home) you will need at list : Dual stack or NAT64/ DNS64
CGN doesn't stop anyone deploying dual stack. NAT64/DNS64 is dead in the water without other mechanisms (464XLAT or alike).
True... But... Resources deploying/maintaining all of these keep IPv4-limping along technologies are resources taken away from IPv6 deployment.
My point is that people seem to scoff at CGN. There is nothing stopping anyone putting in CGN for IPv4 (that has to be done to handle IPv4 address exhaustion), then giving dual stack for end users can be done at any time.
Not really...
Face it, we're running out of IPv4 addresses. For basic Internet subscriptions the IPv4 connectivity is going to be behind CGN. IPv6 is a completely different problem that has little bearing on CGN or not for IPv4. DS-Lite is also CGN, it just happens to be done over IPv6 access. MAP is also CGN.
No, it really isn't. Sufficient IPv6 deployment at the content side would actually allow the subscriber side to be IPv4 or dual-stack for existing customers with new customers receiving IPv6-only. The missing piece there is actually the set-top coversion unit for IPv4-only devices. (Ideally, a dongle which can be plugged into the back of an IPv4-only device with an IPv6-only jack on the other side. Power could be done a number of ways, including POE (with optional injector), USB, or other.
I'm ok with people complaining about lack of IPv6 deployment, but I don't understand people complaining about CGN. What's the alternative?
IPv6 deployment _IS_ the alternative. They are not orthogonal. Owen
If I'm an ISP deploying a network for users today, I effectively have to provide some mechanism to allow those users to get to IPv4 only content. There is way too much stuff out there that is IPv4 only today. Yes, content providers should provide IPv6 access....but if I'm an ISP, I can't really control that aspect. If I provide users with a service that isn't able to connect to 80% of websites (to say nothing of VPN's, corporate email services, etc, that people may need), I'm not going to have a whole lot of business. Now - I completely agree that ISP's must start deploying IPv6 natively. Legacy equipment that doesn't support IPv6 is not an acceptable excuse....its just evidence of poor decision making and short-sighed purchasing decisions. CGN clearly isn't ideal and doesn't mitigate the need for native IPv6 connectivity. But right now, native IPv6 connectivity is still not a substitute for some level of IPv4 connectivity, even if its CGN'ed. Oliver ------------------------------------- Oliver Garraux Check out my blog: blog.garraux.net Follow me on Twitter: twitter.com/olivergarraux On Sun, Apr 7, 2013 at 4:06 PM, Owen DeLong <owen@delong.com> wrote:
On Apr 7, 2013, at 00:31 , Mikael Abrahamsson <swmike@swm.pp.se> wrote:
On Sun, 7 Apr 2013, Fabien Delmotte wrote:
CGN is just a solution to save time, it is not a transition mechanism through IPv6 At the end (IPv6 at home) you will need at list : Dual stack or NAT64/ DNS64
CGN doesn't stop anyone deploying dual stack. NAT64/DNS64 is dead in the water without other mechanisms (464XLAT or alike).
True... But... Resources deploying/maintaining all of these keep IPv4-limping along technologies are resources taken away from IPv6 deployment.
My point is that people seem to scoff at CGN. There is nothing stopping anyone putting in CGN for IPv4 (that has to be done to handle IPv4 address exhaustion), then giving dual stack for end users can be done at any time.
Not really...
Face it, we're running out of IPv4 addresses. For basic Internet subscriptions the IPv4 connectivity is going to be behind CGN. IPv6 is a completely different problem that has little bearing on CGN or not for IPv4. DS-Lite is also CGN, it just happens to be done over IPv6 access. MAP is also CGN.
No, it really isn't. Sufficient IPv6 deployment at the content side would actually allow the subscriber side to be IPv4 or dual-stack for existing customers with new customers receiving IPv6-only. The missing piece there is actually the set-top coversion unit for IPv4-only devices. (Ideally, a dongle which can be plugged into the back of an IPv4-only device with an IPv6-only jack on the other side. Power could be done a number of ways, including POE (with optional injector), USB, or other.
I'm ok with people complaining about lack of IPv6 deployment, but I don't understand people complaining about CGN. What's the alternative?
IPv6 deployment _IS_ the alternative. They are not orthogonal.
Owen
On Apr 7, 2013, at 15:43 , Oliver Garraux <oliver@g.garraux.net> wrote:
If I'm an ISP deploying a network for users today, I effectively have to provide some mechanism to allow those users to get to IPv4 only content. There is way too much stuff out there that is IPv4 only today.
Agreed... However...
Yes, content providers should provide IPv6 access....but if I'm an ISP, I can't really control that aspect. If I provide users with a service that isn't able to connect to 80% of websites (to say nothing of VPN's, corporate email services, etc, that people may need), I'm not going to have a whole lot of business.
I was responding to Mikael's claim that pushing content providers to deploy IPv6 was orthogonal to the need for CGN. Clearly your statement here indicates that you see my point that it is NOT orthogonal, but, in fact the failure of content providers to deploy IPv6 _IS_ the driving cause for CGN.
Now - I completely agree that ISP's must start deploying IPv6 natively. Legacy equipment that doesn't support IPv6 is not an acceptable excuse....its just evidence of poor decision making and short-sighed purchasing decisions. CGN clearly isn't ideal and doesn't mitigate the need for native IPv6 connectivity. But right now, native IPv6 connectivity is still not a substitute for some level of IPv4 connectivity, even if its CGN'ed.
I don't disagree. You are actually making the exact point I was attempting to make. The need for CGN is not divorced from the failure to deploy IPv6, it is caused by it. Owen
Oliver
-------------------------------------
Oliver Garraux Check out my blog: blog.garraux.net Follow me on Twitter: twitter.com/olivergarraux
On Sun, Apr 7, 2013 at 4:06 PM, Owen DeLong <owen@delong.com> wrote:
On Apr 7, 2013, at 00:31 , Mikael Abrahamsson <swmike@swm.pp.se> wrote:
On Sun, 7 Apr 2013, Fabien Delmotte wrote:
CGN is just a solution to save time, it is not a transition mechanism through IPv6 At the end (IPv6 at home) you will need at list : Dual stack or NAT64/ DNS64
CGN doesn't stop anyone deploying dual stack. NAT64/DNS64 is dead in the water without other mechanisms (464XLAT or alike).
True... But... Resources deploying/maintaining all of these keep IPv4-limping along technologies are resources taken away from IPv6 deployment.
My point is that people seem to scoff at CGN. There is nothing stopping anyone putting in CGN for IPv4 (that has to be done to handle IPv4 address exhaustion), then giving dual stack for end users can be done at any time.
Not really...
Face it, we're running out of IPv4 addresses. For basic Internet subscriptions the IPv4 connectivity is going to be behind CGN. IPv6 is a completely different problem that has little bearing on CGN or not for IPv4. DS-Lite is also CGN, it just happens to be done over IPv6 access. MAP is also CGN.
No, it really isn't. Sufficient IPv6 deployment at the content side would actually allow the subscriber side to be IPv4 or dual-stack for existing customers with new customers receiving IPv6-only. The missing piece there is actually the set-top coversion unit for IPv4-only devices. (Ideally, a dongle which can be plugged into the back of an IPv4-only device with an IPv6-only jack on the other side. Power could be done a number of ways, including POE (with optional injector), USB, or other.
I'm ok with people complaining about lack of IPv6 deployment, but I don't understand people complaining about CGN. What's the alternative?
IPv6 deployment _IS_ the alternative. They are not orthogonal.
Owen
On Sun, 7 Apr 2013, Owen DeLong wrote:
I don't disagree. You are actually making the exact point I was attempting to make. The need for CGN is not divorced from the failure to deploy IPv6, it is caused by it.
Absolutely. That doesn't mean that any individual ISP right now can choose to *not* implement CGN and deploy IPv6. That won't solve IPv4 address depletion *for that ISP*. This is an industry-wide failure that no individual part of the industry can work around. For most ISPs, deploying some kind of CGN is the only rational decision at this time. We can discuss what could have should have happened earlier, but now we're here. Yes, ISPs should deploy IPv6. Everybody should deploy IPv6. But I still believe that CGN is mostly orthogonal to IPv6 deployment. Saying ISPs today are wrong to deploy CGN and that they should deploy IPv6 (the word "instead" is usually not there, but it still seems to be implied), I just don't understand that argument. Is it just that the ISP in question hasn't announced their IPv6 plans in the same announcement that is the problem? So that people believe CGN is part of a future-proof strategy? So if the ISP says "we're going to deploy CGN for select customers during 2H-2013 due to IPv4 run-out, and at the same time we're planning to start rolling out IPv6 for customers who have upgradable equipment", does that help? If the ISP has been around for a while, it's still a huge part of the customer base that won't be upgradable, and those customers will be stuck behind NAT444 until they do something. -- Mikael Abrahamsson email: swmike@swm.pp.se
* Owen DeLong
The need for CGN is not divorced from the failure to deploy IPv6, it is caused by it.
In a historical context, this is true enough. If we had accomplished ubiquitous IPv6 deployment ten years ago, there would be no IPv4 depletion, and there would be no CGN. However, that ship has sailed long ago. You're using present tense where you should have used past.
I was responding to Mikael's claim that pushing content providers to deploy IPv6 was orthogonal to the need for CGN.
If we put down the history books and focus on today's operational realities, it *is* orthogonal. If you're an ISP fresh out of IPv4 addresses today, "pushing content providers to deploy IPv6" is simply not a realistic strategy to deal with it. CGN is.
Clearly your statement here indicates that you see my point that it is NOT orthogonal, but, in fact the failure of content providers to deploy IPv6 _IS_ the driving cause for CGN.
I'm not sure why you are singling out content providers, BTW. There are no shortage of other things out there that have an absolute hard requirement on IPv4 to function properly. Gaming consoles, Android phones and tables, iOS phones and tablets[1], home gateways, software and apps, embedded devices, ... - the list goes on and on. If the only missing piece of the puzzle was the lack of IPv6 support at the content providers' side, IPv6+NAT64 would constitute a perfectly viable residential/cellular internet service. As far as I know, however, not a single provider is seriously considering this strategy going forward. That's telling. Tore [1] From what I hear, anyway. They used to work fine on IPv6-only wireless networks, I've seen it myself, but I've been told that it's taken a turn for the worse over the course of the last year.
On Apr 7, 2013, at 23:27 , Tore Anderson <tore@fud.no> wrote:
* Owen DeLong
The need for CGN is not divorced from the failure to deploy IPv6, it is caused by it.
In a historical context, this is true enough. If we had accomplished ubiquitous IPv6 deployment ten years ago, there would be no IPv4 depletion, and there would be no CGN. However, that ship has sailed long ago. You're using present tense where you should have used past.
Respectfully, I disagree. If the major content providers were to deploy IPv6 within the next 6 months (pretty achievable even now), then the need for CGN would at least be very much reduced, if not virtually eliminated.
I was responding to Mikael's claim that pushing content providers to deploy IPv6 was orthogonal to the need for CGN.
If we put down the history books and focus on today's operational realities, it *is* orthogonal. If you're an ISP fresh out of IPv4 addresses today, "pushing content providers to deploy IPv6" is simply not a realistic strategy to deal with it. CGN is.
This does not represent a reason to stop pushing content providers. While CGN may be a necessary stop-gap measure today for some, there are many more who aren't facing that decision for a few months. Even for those that do have to deploy it, the reality is that CGN is fragile, unwieldy, expensive, and high-maintenance. Further, it provides a lousy customer experience. The less you have to depend on CGN as an ISP, the better your life will be. As such, it is even more vital today than it was in history to keep the pressure for IPv6 content strong.
Clearly your statement here indicates that you see my point that it is NOT orthogonal, but, in fact the failure of content providers to deploy IPv6 _IS_ the driving cause for CGN.
I'm not sure why you are singling out content providers, BTW. There are no shortage of other things out there that have an absolute hard requirement on IPv4 to function properly. Gaming consoles, Android phones and tables, iOS phones and tablets[1], home gateways, software and apps, embedded devices, ... - the list goes on and on.
All of those things are actually driven primarily by content. iOS phones and tables are perfectly capable of IPv6 where IPv6 is available over WiFi. iPhone 5 can do IPv6 over the carrier network. I know, my iPhone 5 works great with IPv6 on its network. Home gateways are going to need to be replaced. There are plenty of them that do support IPv6. Gaming consoles are entirely under the control of content providers. Most of the embedded devices are either going to need to be replaced over time, upgraded, or we're going to need some form of set-top box to deal with them in the future. Bottom line, content providers are the low-hanging fruit in terms of the easiest and fastest way to have the biggest impact in reducing the need for and load on CGN deployments.
If the only missing piece of the puzzle was the lack of IPv6 support at the content providers' side, IPv6+NAT64 would constitute a perfectly viable residential/cellular internet service. As far as I know, however, not a single provider is seriously considering this strategy going forward. That's telling.
It's not the only piece, just the easiest one to solve immediately with the biggest payoff.
Tore
[1] From what I hear, anyway. They used to work fine on IPv6-only wireless networks, I've seen it myself, but I've been told that it's taken a turn for the worse over the course of the last year.
Actually it took a brief turn for the worse due to a bug which has now been (partially) resolved. Apparently the phones used to prefer IPv6 over carrier if they were on a wireless v4-only network which ran up some (startling) data charges for some users. Now they've made it so that if you have a wifi connection, you simply won't use the cellular network no matter what. This unfortunately means that you cannot surf an IPv6-only site while you are connected to an IPv4-only wifi network even if you have dual-stack carrier connectivity, but I think that's a reasonable tradeoff for now. Prior to this latest software/carrier settings update, they had simply turned off IPv6 on the carrier side, but the wifi side has always worked since one of the later versions of IOS4 or one of the earlier versions of IOS5, I forget which. Owen

On Mon Apr 08, 2013 at 01:41:34AM -0700, Owen DeLong wrote:
Respectfully, I disagree. If the major content providers were to deploy IPv6 within the next 6 months (pretty achievable even now), then the need for CGN would at least be very much reduced, if not virtually eliminated.
Surely the case is that you've still got the same number of users who need an IPv4 address to be able to access "legacy" IPv4 sites on the Internet - until 100% of content is accessible via IPv6. What it does, however, change is the amount of traffic which would need to flow through a CGN box. Unfortunately, CGN is here until either everything is available over IPv6, or a better version of NAT64 which doesn't depend on DNS rewriting is designed and deployed. Simon

On 4/8/13 9:41 AM, Owen DeLong wrote:
On Apr 7, 2013, at 23:27 , Tore Anderson <tore@fud.no> wrote:
* Owen DeLong
The need for CGN is not divorced from the failure to deploy IPv6, it is caused by it.
In a historical context, this is true enough. If we had accomplished ubiquitous IPv6 deployment ten years ago, there would be no IPv4 depletion, and there would be no CGN. However, that ship has sailed long ago. You're using present tense where you should have used past.
Respectfully, I disagree. If the major content providers were to deploy IPv6 within the next 6 months (pretty achievable even now), then the need for CGN would at least be very much reduced, if not virtually eliminated.
I though that they have done it last year around June 8th. ;-) In fact, the need for CGN has been reduced if you count that 30-40% of your traffic would go to those places. Although CGN is going to be a necessary evil, deploying CGN without IPv6 would be a mistake IMHO. /as
* Owen DeLong
Respectfully, I disagree. If the major content providers were to deploy IPv6 within the next 6 months (pretty achievable even now), then the need for CGN would at least be very much reduced, if not virtually eliminated.
I agree with "very much reduced". However, and IMHO, "virtually eliminated" is completely unrealistic.
The less you have to depend on CGN as an ISP, the better your life will be.
As such, it is even more vital today than it was in history to keep the pressure for IPv6 content strong. [...] Bottom line, content providers are the low-hanging fruit in terms of the easiest and fastest way to have the biggest impact in reducing the need for and load on CGN deployments.
If the only missing piece of the puzzle was the lack of IPv6 support at the content providers' side, IPv6+NAT64 would constitute a perfectly viable residential/cellular internet service. As far as I know, however, not a single provider is seriously considering this strategy going forward. That's telling.
It's not the only piece, just the easiest one to solve immediately with the biggest payoff.
I agree fully that the continued deployment of IPv6 on the content side and all other places is a benefit to any ISP that is providing IPv6 to their subscribers alongside CGN. The payoff is reduced customer unhappiness due to the effects of CGN, and reducing the amount of investment in CGN necessary. But the payoff is not going to be avoiding to have to implement CGN (or similar IPv4 life-support mechanisms, including MAP) in the first place, no matter how hard one pushes for IPv6. In order for that that to be the case, *all* the missing pieces must fall in place, not only the biggest/easiest ones - and there's simply too many small and tricky ones left, and too little time. I cannot see any realistic outcome of the ordeal we're currently in that does not include CGN or similar stuff to handle the long tail of IPv4-only stuff. It's simply too late for IPv6 to prevent CGN. I'd be absolutely delighted, though, if I'm wrong and you're able to say to me a few years from now «I told you so»! :-) Tore

In a message written on Mon, Apr 08, 2013 at 01:41:34AM -0700, Owen DeLong wrote:
Respectfully, I disagree. If the major content providers were to deploy IPv6 within the next 6 months (pretty achievable even now), then the need for CGN would at least be very much reduced, if not virtually eliminated.
I'm going to disagree, because the tail here I think is quite long. Owen is spot on when looking at the percentage of bits moved across the network. I suspect if the top 20 CDN's were to IPv6 enable _everything_ that 50-90% of the bits in most networks would be moved over native IPv6, depending on the exact mix of traffic in the network. However, CDN's are a _very_ small part of the address space. I'd be surprised if the top 20 CDN's had 0.01% of all IPv4 space. That leaves a lot of hosts that need to be upgraded. There's a lot of people who buy a $9.95/month VPS to host their personal blog read by 20 people who don't know anything about IPv4 or IPv6 but want to be able to reach their site. The traffic level may be non-interesting, but they will be quite unhappy without a CGN solution. Moving the CDN's to IPv6 native has the potential to save the access providers a TON of money on CGN hardware, due to the bandwidth involved. However those access providers still have to do CGN, otherwise their NOC's will be innondated with complaints about the inability to reach a bunch of small sites for a long period of time. If I were deploying CGN, I would be exerting any leverage I had on CDN's to go native IPv6. -- Leo Bicknell - bicknell@ufp.org - CCIE 3440 PGP keys at http://www.ufp.org/~bicknell/
DS-Lite is also CGN, it just happens to be done over IPv6 access. MAP is also CGN.
Thankfully, MAP is not CGN. Correctly stated, unlike DS-Lite, MAP doesn't require any CGN that causes the SP network to put up with the NAT state. This means that all the subsequent issues of CGN/DS-Lite no longer apply. MAP is all about stateless (NAT64 of Encapsulation) and IPv6 enabled access. MAP makes much more sense in any SP network having its internet customers do IPv4 address sharing and embrace IPv6. Cheers, Rajiv Sent from my Phone On Apr 7, 2013, at 3:33 AM, "Mikael Abrahamsson" <swmike@swm.pp.se> wrote:
On Sun, 7 Apr 2013, Fabien Delmotte wrote:
CGN is just a solution to save time, it is not a transition mechanism through IPv6 At the end (IPv6 at home) you will need at list : Dual stack or NAT64/ DNS64
CGN doesn't stop anyone deploying dual stack. NAT64/DNS64 is dead in the water without other mechanisms (464XLAT or alike).
My point is that people seem to scoff at CGN. There is nothing stopping anyone putting in CGN for IPv4 (that has to be done to handle IPv4 address exhaustion), then giving dual stack for end users can be done at any time.
Face it, we're running out of IPv4 addresses. For basic Internet subscriptions the IPv4 connectivity is going to be behind CGN. IPv6 is a completely different problem that has little bearing on CGN or not for IPv4. DS-Lite is also CGN, it just happens to be done over IPv6 access. MAP is also CGN.
I'm ok with people complaining about lack of IPv6 deployment, but I don't understand people complaining about CGN. What's the alternative?
-- Mikael Abrahamsson email: swmike@swm.pp.se

MAP is all about stateless (NAT64 of Encapsulation) and IPv6 enabled access. MAP makes much more sense in any SP network having its internet customers do IPv4 address sharing and embrace IPv6.
What may make 'much more sense' in one network, doesn't necessarily make as much since in another network. As I understand it, MAP requires at least a software change on existing CPE, if not wholesale CPE change. Some providers may prefer to implement CGN instead if the capital outlay is less (and providing new CPE to customers through walkins or truck rolls can be problematic). Our plan for my company at this time is to deploy native IPv4+IPv6 to all customers. While we are doing that, continue discussions and testing with CGN providers so that when we are unable to obtain anymore IPv4 addresses, we can then deploy CGN. Our hope is that we never get to the point of having to go CGN but we have to be ready in case that day comes and have our implementation and opt-out (if available) processes ready. What devices does Cisco support MAP on? Specifically, does the DPC3827 support it? sam
Sam,
What may make 'much more sense' in one network, doesn't necessarily make as much since in another network. As I understand it, MAP requires at least a software change on existing CPE, if not wholesale CPE change. Some providers may prefer to implement CGN instead if the capital outlay is less (and providing new CPE to customers through walkins or truck rolls can be problematic).
I agree with you. Having said that, the way many ISPs are approaching the MAP deployment is by letting the new customers get the MAP capable CPE from the get go, while letting the existing customers' get their CPE routers upgraded when/if they need a truck roll or through regular S&H (much like how Vonage does it). It is certainly very much possible to get MAP functionality by software upgrades, though the mileage may vary.
What devices does Cisco support MAP on? Specifically, does the DPC3827 support it?
MAP BR function is supported on ASR9K and ASR1K. I am not aware of MAP CE function support on DPC3827 CPE router. Cheers, Rajiv -----Original Message----- From: "<Sam Hayes Merritt>", III <sam@themerritts.org> Date: Sunday, April 7, 2013 10:56 PM To: Rajiv Asati <rajiva@cisco.com> Cc: nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
MAP is all about stateless (NAT64 of Encapsulation) and IPv6 enabled access. MAP makes much more sense in any SP network having its internet customers do IPv4 address sharing and embrace IPv6.
What may make 'much more sense' in one network, doesn't necessarily make as much since in another network. As I understand it, MAP requires at least a software change on existing CPE, if not wholesale CPE change. Some providers may prefer to implement CGN instead if the capital outlay is less (and providing new CPE to customers through walkins or truck rolls can be problematic).
Our plan for my company at this time is to deploy native IPv4+IPv6 to all customers. While we are doing that, continue discussions and testing with CGN providers so that when we are unable to obtain anymore IPv4 addresses, we can then deploy CGN. Our hope is that we never get to the point of having to go CGN but we have to be ready in case that day comes and have our implementation and opt-out (if available) processes ready.
What devices does Cisco support MAP on? Specifically, does the DPC3827 support it?
sam
On Mon, 8 Apr 2013, Rajiv Asati (rajiva) wrote:
Thankfully, MAP is not CGN. Correctly stated, unlike DS-Lite, MAP doesn't require any CGN that causes the SP network to put up with the NAT state. This means that all the subsequent issues of CGN/DS-Lite no longer apply.
For me as an operator, MAP is most likely going to be implemented in a CGN-like box. Yes, it's stateless. Doesn't matter, I still need to flow traffic through a dedicated box because MAP won't be implemented in my regular routers (if you know otherwise, please speak up).
MAP is all about stateless (NAT64 of Encapsulation) and IPv6 enabled access. MAP makes much more sense in any SP network having its internet customers do IPv4 address sharing and embrace IPv6.
It's still NAT. -- Mikael Abrahamsson email: swmike@swm.pp.se
* Mikael Abrahamsson
On Mon, 8 Apr 2013, Rajiv Asati (rajiva) wrote:
MAP is all about stateless (NAT64 of Encapsulation) and IPv6 enabled access. MAP makes much more sense in any SP network having its internet customers do IPv4 address sharing and embrace IPv6.
It's still NAT.
AIUI, the standards-track flavour of MAP, MAP-E, is *not* NAT - it is tunneling, pure encap/decap plus a clever way to calculate the outer IPv6 src/dst addresses from the inner IPv4 addresses and ports. The inner IPv4 packets are not modified by the centralised MAP tunneling routers, so there is no "Network Address Translation" being performed. The tunnel endpoint will 99.99% of cases be a CPE with a NAPT44 component though, so there is some NAT involved in the overall solution, but it's pretty much the same as what we have in today's CPEs/HGWs. The only significant difference is that a MAP CPE must be prepared to not being able to use all the 65536 source ports. Tore
On Mon, 8 Apr 2013, Tore Anderson wrote:
* Mikael Abrahamsson
On Mon, 8 Apr 2013, Rajiv Asati (rajiva) wrote:
MAP is all about stateless (NAT64 of Encapsulation) and IPv6 enabled access. MAP makes much more sense in any SP network having its internet customers do IPv4 address sharing and embrace IPv6.
It's still NAT.
AIUI, the standards-track flavour of MAP, MAP-E, is *not* NAT - it is tunneling, pure encap/decap plus a clever way to calculate the outer IPv6 src/dst addresses from the inner IPv4 addresses and ports. The inner IPv4 packets are not modified by the centralised MAP tunneling routers, so there is no "Network Address Translation" being performed.
This is all splitting hairs. Yes, the outside port addresses do not change but however the src/dst addresses change (=translated), right? Does anyone see MAP-E being implemented on regular linecards or is it going to be implemented on processor based dedicated hardware? At least initially, I would just assume it's going to be some kind of CGN blade.
The tunnel endpoint will 99.99% of cases be a CPE with a NAPT44 component though, so there is some NAT involved in the overall solution, but it's pretty much the same as what we have in today's CPEs/HGWs. The only significant difference is that a MAP CPE must be prepared to not being able to use all the 65536 source ports.
Yes, MAP-E needs CPE support, thus hard to deploy short term. Long term, yes, really nice. Perfect for long tail IPv4 reachability over IPv6 access networks. -- Mikael Abrahamsson email: swmike@swm.pp.se
* Mikael Abrahamsson
On Mon, 8 Apr 2013, Tore Anderson wrote:
AIUI, the standards-track flavour of MAP, MAP-E, is *not* NAT - it is tunneling, pure encap/decap plus a clever way to calculate the outer IPv6 src/dst addresses from the inner IPv4 addresses and ports. The inner IPv4 packets are not modified by the centralised MAP tunneling routers, so there is no "Network Address Translation" being performed.
This is all splitting hairs. Yes, the outside port addresses do not change but however the src/dst addresses change (=translated), right?
There is no outside port addresses. The Next Header field in the outside IPv6 header is set to 4 (i.e., what follows next is an IPv4 header). This inner IPv4 header (and the payload following it) is the original one and completely unmodified and not translated/rewritten in any way by the ISP's MAP gateway. AIUI, anyway. So unless you mean that the src/dst address "change" or "are translated" due to the addresses in the outer IPv6 header are not the same as in the inner IPv4 header, there is simply is no translation happening here. If this is to be called "translation", then any tunneling mechanism that works by stacking layer-3 headers, including GRE, IPIP, ESP, and proto-41, must be also called "translation".
Does anyone see MAP-E being implemented on regular linecards or is it going to be implemented on processor based dedicated hardware? At least initially, I would just assume it's going to be some kind of CGN blade.
No idea, sorry. Tore
* Tore Anderson
Does anyone see MAP-E being implemented on regular linecards or is it going to be implemented on processor based dedicated hardware? At least initially, I would just assume it's going to be some kind of CGN blade.
No idea, sorry.
https://ripe65.ripe.net/presentations/91-townsley-map-ripe65-ams-sept-24-201... slide 15: «Processed inline with normal IP traffic (at least on Cisco’s ASR9K)» Tore
On Mon, 8 Apr 2013, Tore Anderson wrote:
If this is to be called "translation", then any tunneling mechanism that works by stacking layer-3 headers, including GRE, IPIP, ESP, and proto-41, must be also called "translation".
Oki, my bad. I read https://ripe65.ripe.net/presentations/91-townsley-map-ripe65-ams-sept-24-201... and obviously didn't understand. I thought only the payload was encapsulated, not the complete IPv4 packet. It said "replace IPv4 header with IPv6 header" and I missed that this was for MAP-T, not MAP-E). Thanks for explaining. I understand why MAP-E is not translation now. -- Mikael Abrahamsson email: swmike@swm.pp.se

* Tore Anderson
The tunnel endpoint will 99.99% of cases be a CPE with a NAPT44 component though, so there is some NAT involved in the overall solution, but it's pretty much the same as what we have in today's CPEs/HGWs. The only significant difference is that a MAP CPE must be prepared to not being able to use all the 65536 source ports.
BTW. It is AIUI quite possible with MAP to provision a "whole" IPv4 address or even a prefix to the subscriber, thus also taking away the need for [srcport-restricted] NAPT44 in the CPE. I find that the easiest way to visualise MAP is to take the 16 bits of TCP/UDP port space, and bolt it onto the end of the 32 bits of the IPv4 address space, for a total of 48 "routable" bits. So while the primary use case for MAP is to provision less than 32 bits to the individual customers (say a "/34" -> 4 subscribers per IPv4 address w/16k ports each), you can also give out a "whole" /32 or a /24 or whatever - perhaps only to the customers that are willing to pay for the privilege. I haven't tested, but I believe that if you were to hook up a standard Linux box to a ISP that provides /32 or shorter over MAP, you don't really need any special MAP support in the IP stack to make it go - you'd have to calculate the addresses to be used yourself, but once you've got them, you could just configure everything using standard "ip tunnel/address" commands. It's quite neat, I think. :-) Tore

On 4/8/2013 7:20 AM, Tore Anderson wrote:
BTW. It is AIUI quite possible with MAP to provision a "whole" IPv4 address or even a prefix to the subscriber, thus also taking away the need for [srcport-restricted] NAPT44 in the CPE.
The problem is NAPT44 in the CPE isn't enough. We are reaching the point that 1 IPv4 Address per customer won't accommodate user bases. The larger issue I think with MAP is CPE support requirements. There are ISP layouts that use bridging instead of CPE routers (which was a long term design to support IPv6 without CPE replacements years later). CGN will handle the IPv4 issues in this setup just fine. Then there are those who have already deployed IPv6 capable CPEs with PPP or DHCP in a router configuration which does not have MAP support. Given the variety of CPE vendors that end up getting deployed over a longer period of time, it is easier and more cost effective to deploy CGN than try and replace all the CPEs. Given US$35/CPE, cost for replacements (not including deployment costs) for 20k users is US$700k. CGN gear suddenly doesn't seem so costly. The only way I see it justifiable is if you haven't had IPv6 deployment in mind yet and you are having to replace every CPE for IPv6 support anyways, you might go with a MAPS/IPv6 aware CPE which the customer pays for if they wish IPv6 connectivity(or during whatever slow trickle replacement methods you utilize). While waiting for the slow rollout, CGN would be an interim cost that would be acceptable. I'm not sure there is a reason for MAPS if you've already deployed CGN, though. I am sure Verizon did a lot of cost analysis. Jack

On 4/8/13 7:23 AM, Jack Bates wrote:
On 4/8/2013 7:20 AM, Tore Anderson wrote:
BTW. It is AIUI quite possible with MAP to provision a "whole" IPv4 address or even a prefix to the subscriber, thus also taking away the need for [srcport-restricted] NAPT44 in the CPE.
The problem is NAPT44 in the CPE isn't enough. We are reaching the point that 1 IPv4 Address per customer won't accommodate user bases.
That happened a long time ago. I realize the people like to think of wireless providers as different, they really aren't. A big chuck of our mobile gaming customers come to us via carrier operated nat translators. Some of them now come to us via ipv6, most do not.
The larger issue I think with MAP is CPE support requirements. There are ISP layouts that use bridging instead of CPE routers (which was a long term design to support IPv6 without CPE replacements years later). CGN will handle the IPv4 issues in this setup just fine. Then there are those who have already deployed IPv6 capable CPEs with PPP or DHCP in a router configuration which does not have MAP support. Given the variety of CPE vendors that end up getting deployed over a longer period of time, it is easier and more cost effective to deploy CGN than try and replace all the CPEs.
Given US$35/CPE, cost for replacements (not including deployment costs) for 20k users is US$700k. CGN gear suddenly doesn't seem so costly.
The only way I see it justifiable is if you haven't had IPv6 deployment in mind yet and you are having to replace every CPE for IPv6 support anyways, you might go with a MAPS/IPv6 aware CPE which the customer pays for if they wish IPv6 connectivity(or during whatever slow trickle replacement methods you utilize). While waiting for the slow rollout, CGN would be an interim cost that would be acceptable. I'm not sure there is a reason for MAPS if you've already deployed CGN, though.
I am sure Verizon did a lot of cost analysis.
Jack
On 4/8/2013 9:58 AM, joel jaeggli wrote:
That happened a long time ago. I realize the people like to think of wireless providers as different, they really aren't. A big chuck of our mobile gaming customers come to us via carrier operated nat translators. Some of them now come to us via ipv6, most do not.
Yeah, forgive me. I have a tendency to forget the mobile carriers, probably because some of them started with CGN. One of my customers just started a new cell network. He's burning through /20's like they are nothing in a short time frame (and it's a small geographic area). They're deploying CGN so we don't run out of addresses and can recover what we've already burned through. IPv6 for their cellular didn't seem high priority either. Jack
On Apr 8, 2013, at 07:58 , joel jaeggli <joelja@bogus.com> wrote:
On 4/8/13 7:23 AM, Jack Bates wrote:
On 4/8/2013 7:20 AM, Tore Anderson wrote:
BTW. It is AIUI quite possible with MAP to provision a "whole" IPv4 address or even a prefix to the subscriber, thus also taking away the need for [srcport-restricted] NAPT44 in the CPE.
The problem is NAPT44 in the CPE isn't enough. We are reaching the point that 1 IPv4 Address per customer won't accommodate user bases.
That happened a long time ago. I realize the people like to think of wireless providers as different, they really aren't. A big chuck of our mobile gaming customers come to us via carrier operated nat translators. Some of them now come to us via ipv6, most do not.
The larger issue I think with MAP is CPE support requirements. There are ISP layouts that use bridging instead of CPE routers (which was a long term design to support IPv6 without CPE replacements years later). CGN will handle the IPv4 issues in this setup just fine. Then there are those who have already deployed IPv6 capable CPEs with PPP or DHCP in a router configuration which does not have MAP support. Given the variety of CPE vendors that end up getting deployed over a longer period of time, it is easier and more cost effective to deploy CGN than try and replace all the CPEs.
Given US$35/CPE, cost for replacements (not including deployment costs) for 20k users is US$700k. CGN gear suddenly doesn't seem so costly.
The only way I see it justifiable is if you haven't had IPv6 deployment in mind yet and you are having to replace every CPE for IPv6 support anyways, you might go with a MAPS/IPv6 aware CPE which the customer pays for if they wish IPv6 connectivity(or during whatever slow trickle replacement methods you utilize). While waiting for the slow rollout, CGN would be an interim cost that would be acceptable. I'm not sure there is a reason for MAPS if you've already deployed CGN, though.
I am sure Verizon did a lot of cost analysis.
Jack
There is actually a key difference. In the US, at least, everyone is used to the cellular networks mostly sucking. They are willing to put up with far more degraded service over wireless than they will tolerate on a wired connection. You and I and everyone else on this list realize that this is complete BS, but the majority of the general public tolerates it, so it persists. Owen

Indeed MAP-E requires CPE replacement/upgrade cost. But I would like to share JANOG Softwire WG Activity. http://conference.apnic.net/__data/assets/pdf_file/0005/58856/apnic35-janog-... MAP-E already supported by 6 vendors,7 implementations. It includes 2 open source(OpenWRT and ASAMAP) and 2 kernel(Linux 2.6.18 and NetBSD 4.0.1). Regards, Shishio (2013/04/08 23:23), Jack Bates wrote:
On 4/8/2013 7:20 AM, Tore Anderson wrote:
BTW. It is AIUI quite possible with MAP to provision a "whole" IPv4 address or even a prefix to the subscriber, thus also taking away the need for [srcport-restricted] NAPT44 in the CPE.
The problem is NAPT44 in the CPE isn't enough. We are reaching the point that 1 IPv4 Address per customer won't accommodate user bases.
The larger issue I think with MAP is CPE support requirements. There are ISP layouts that use bridging instead of CPE routers (which was a long term design to support IPv6 without CPE replacements years later). CGN will handle the IPv4 issues in this setup just fine. Then there are those who have already deployed IPv6 capable CPEs with PPP or DHCP in a router configuration which does not have MAP support. Given the variety of CPE vendors that end up getting deployed over a longer period of time, it is easier and more cost effective to deploy CGN than try and replace all the CPEs.
Given US$35/CPE, cost for replacements (not including deployment costs) for 20k users is US$700k. CGN gear suddenly doesn't seem so costly.
The only way I see it justifiable is if you haven't had IPv6 deployment in mind yet and you are having to replace every CPE for IPv6 support anyways, you might go with a MAPS/IPv6 aware CPE which the customer pays for if they wish IPv6 connectivity(or during whatever slow trickle replacement methods you utilize). While waiting for the slow rollout, CGN would be an interim cost that would be acceptable. I'm not sure there is a reason for MAPS if you've already deployed CGN, though.
I am sure Verizon did a lot of cost analysis.
Jack
.
Jack, I am assuming that you meant MAP, when you wrote MAPS.
The larger issue I think with MAP is CPE support requirements. There are ISP layouts that use bridging instead of CPE routers (which was a long term design to support IPv6 without CPE replacements years later). CGN will handle the IPv4 issues in this setup just fine. Then there are
I agree. Good point, btw. This is the classical ISP deployment model, in which the ISP would usually provide the layer2 modem, and let the customer get the retail CPE.
those who have already deployed IPv6 capable CPEs with PPP or DHCP in a router configuration which does not have MAP support. Given the variety of CPE vendors that end up getting deployed over a longer period of time, it is easier and more cost effective to deploy CGN than try and replace all the CPEs.
Seemingly so, until we start adding up the cost of - Logging infrastructure (setup & mtc) - Static NAT & Port forwarding (gaming, camera, etc.) - CGN redundancy & load-sharing - design complexity (to maintain symmetry) - ..
Given US$35/CPE, cost for replacements (not including deployment costs) for 20k users is US$700k. CGN gear suddenly doesn't seem so costly.
Let's throw some numbers of the above costs and then we can do the apple-to-apple comparison. Else, you are right that CGN cost could be a lot less. Cheers, Rajiv -----Original Message----- From: Jack Bates <jbates@brightok.net> Date: Monday, April 8, 2013 10:23 AM To: Tore Anderson <tore@fud.no> Cc: nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
On 4/8/2013 7:20 AM, Tore Anderson wrote:
BTW. It is AIUI quite possible with MAP to provision a "whole" IPv4 address or even a prefix to the subscriber, thus also taking away the need for [srcport-restricted] NAPT44 in the CPE.
The problem is NAPT44 in the CPE isn't enough. We are reaching the point that 1 IPv4 Address per customer won't accommodate user bases.
The larger issue I think with MAP is CPE support requirements. There are ISP layouts that use bridging instead of CPE routers (which was a long term design to support IPv6 without CPE replacements years later). CGN will handle the IPv4 issues in this setup just fine. Then there are those who have already deployed IPv6 capable CPEs with PPP or DHCP in a router configuration which does not have MAP support. Given the variety of CPE vendors that end up getting deployed over a longer period of time, it is easier and more cost effective to deploy CGN than try and replace all the CPEs.
Given US$35/CPE, cost for replacements (not including deployment costs) for 20k users is US$700k. CGN gear suddenly doesn't seem so costly.
The only way I see it justifiable is if you haven't had IPv6 deployment in mind yet and you are having to replace every CPE for IPv6 support anyways, you might go with a MAPS/IPv6 aware CPE which the customer pays for if they wish IPv6 connectivity(or during whatever slow trickle replacement methods you utilize). While waiting for the slow rollout, CGN would be an interim cost that would be acceptable. I'm not sure there is a reason for MAPS if you've already deployed CGN, though.
I am sure Verizon did a lot of cost analysis.
Jack
Tore,
I haven't tested, but I believe that if you were to hook up a standard Linux box to a ISP that provides /32 or shorter over MAP, you don't
Yes, indeed. In fact, almost all of the MAP CE implementations (that I am aware of) are open source/linux based - http://enog.jp/~masakazu/vyatta/map/ http://mapt.ivi2.org:8039/readme.txt Cheers, Rajiv -----Original Message----- From: Tore Anderson <tore@fud.no> Date: Monday, April 8, 2013 8:20 AM To: Mikael Abrahamsson <swmike@swm.pp.se>, nanog list <nanog@nanog.org> Cc: Rajiv Asati <rajiva@cisco.com> Subject: Re: Verizon DSL moving to CGN
* Tore Anderson
The tunnel endpoint will 99.99% of cases be a CPE with a NAPT44 component though, so there is some NAT involved in the overall solution, but it's pretty much the same as what we have in today's CPEs/HGWs. The only significant difference is that a MAP CPE must be prepared to not being able to use all the 65536 source ports.
BTW. It is AIUI quite possible with MAP to provision a "whole" IPv4 address or even a prefix to the subscriber, thus also taking away the need for [srcport-restricted] NAPT44 in the CPE.
I find that the easiest way to visualise MAP is to take the 16 bits of TCP/UDP port space, and bolt it onto the end of the 32 bits of the IPv4 address space, for a total of 48 "routable" bits. So while the primary use case for MAP is to provision less than 32 bits to the individual customers (say a "/34" -> 4 subscribers per IPv4 address w/16k ports each), you can also give out a "whole" /32 or a /24 or whatever - perhaps only to the customers that are willing to pay for the privilege.
I haven't tested, but I believe that if you were to hook up a standard Linux box to a ISP that provides /32 or shorter over MAP, you don't really need any special MAP support in the IP stack to make it go - you'd have to calculate the addresses to be used yourself, but once you've got them, you could just configure everything using standard "ip tunnel/address" commands.
It's quite neat, I think. :-)
Tore
Tore is spot on. With MAP, you can use your regular routers, whether it is the Encap mode or Translation mode. One can decide between Encap mode and Translation mode of MAP per his/her environment/requirements. I do find -T mode preferable since it requires no changes to the transparent caching infrastructure or LI infrastructure or QOS policies (if used between CE and Border routers). One may refer to additional details here - http://www.cisco.com/en/US/prod/collateral/iosswrel/ps6537/ps6553/white_pap er_c11-558744-00.html#wp9000119 http://www.ciscoknowledgenetwork.com/files/300_11-06-2012-NGN-IPv4-Exhaust- IPv6-Strategy.pdf Cheers, Rajiv -----Original Message----- From: Tore Anderson <tore@fud.no> Date: Monday, April 8, 2013 6:29 AM To: Mikael Abrahamsson <swmike@swm.pp.se> Cc: Rajiv Asati <rajiva@cisco.com>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
* Mikael Abrahamsson
On Mon, 8 Apr 2013, Rajiv Asati (rajiva) wrote:
MAP is all about stateless (NAT64 of Encapsulation) and IPv6 enabled access. MAP makes much more sense in any SP network having its internet customers do IPv4 address sharing and embrace IPv6.
It's still NAT.
AIUI, the standards-track flavour of MAP, MAP-E, is *not* NAT - it is tunneling, pure encap/decap plus a clever way to calculate the outer IPv6 src/dst addresses from the inner IPv4 addresses and ports. The inner IPv4 packets are not modified by the centralised MAP tunneling routers, so there is no "Network Address Translation" being performed.
The tunnel endpoint will 99.99% of cases be a CPE with a NAPT44 component though, so there is some NAT involved in the overall solution, but it's pretty much the same as what we have in today's CPEs/HGWs. The only significant difference is that a MAP CPE must be prepared to not being able to use all the 65536 source ports.
Tore
CGN-like box. Yes, it's stateless. Doesn't matter, I still need to flow traffic through a dedicated box because MAP won't be implemented in my regular routers (if you know otherwise, please speak up).
Yes, MAP (T-Translation or E-Encap mode) is implemented on two regular routers that I know of - ASR9K and ASR1K. Without that, you are right that MAP wouldn't have been as beneficial as claimed.
It's still NAT.
Yes, assuming MAP-T. No, assuming, MAP-E Cheers, Rajiv -----Original Message----- From: Mikael Abrahamsson <swmike@swm.pp.se> Organization: People's Front Against WWW Date: Monday, April 8, 2013 6:01 AM To: Rajiv Asati <rajiva@cisco.com> Cc: nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
On Mon, 8 Apr 2013, Rajiv Asati (rajiva) wrote:
Thankfully, MAP is not CGN. Correctly stated, unlike DS-Lite, MAP doesn't require any CGN that causes the SP network to put up with the NAT state. This means that all the subsequent issues of CGN/DS-Lite no longer apply.
For me as an operator, MAP is most likely going to be implemented in a CGN-like box. Yes, it's stateless. Doesn't matter, I still need to flow traffic through a dedicated box because MAP won't be implemented in my regular routers (if you know otherwise, please speak up).
MAP is all about stateless (NAT64 of Encapsulation) and IPv6 enabled access. MAP makes much more sense in any SP network having its internet customers do IPv4 address sharing and embrace IPv6.
It's still NAT.
-- Mikael Abrahamsson email: swmike@swm.pp.se
On Mon, Apr 8, 2013 at 2:19 PM, Rajiv Asati (rajiva) <rajiva@cisco.com>wrote:
Yes, MAP (T-Translation or E-Encap mode) is implemented on two regular routers that I know of - ASR9K and ASR1K. Without that, you are right that MAP wouldn't have been as beneficial as claimed.
glad it's cross platform... is it also IP encumbered so it'll remain just as 'cross platform' ?
Chris, UmmmŠ you mean the IPv6 and IPv4 inter-dependency when you say IP encumbered? If so, the answer is Yes. v6 addressing doesn't need to change to accommodate this IPv4 A+P encoding. Cheers, Rajiv -----Original Message----- From: Christopher Morrow <morrowc.lists@gmail.com> Date: Monday, April 8, 2013 2:28 PM To: Rajiv Asati <rajiva@cisco.com> Cc: Mikael Abrahamsson <swmike@swm.pp.se>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
On Mon, Apr 8, 2013 at 2:19 PM, Rajiv Asati (rajiva) <rajiva@cisco.com> wrote:
Yes, MAP (T-Translation or E-Encap mode) is implemented on two regular routers that I know of - ASR9K and ASR1K. Without that, you are right that MAP wouldn't have been as beneficial as claimed.
glad it's cross platform... is it also IP encumbered so it'll remain just as 'cross platform' ?

I think he means patent encumbered. On Mon, Apr 08, 2013 at 07:13:11PM +0000, Rajiv Asati (rajiva) wrote:
Chris,
UmmmŠ you mean the IPv6 and IPv4 inter-dependency when you say IP encumbered?
If so, the answer is Yes. v6 addressing doesn't need to change to accommodate this IPv4 A+P encoding.
Cheers, Rajiv
-----Original Message----- From: Christopher Morrow <morrowc.lists@gmail.com> Date: Monday, April 8, 2013 2:28 PM To: Rajiv Asati <rajiva@cisco.com> Cc: Mikael Abrahamsson <swmike@swm.pp.se>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
On Mon, Apr 8, 2013 at 2:19 PM, Rajiv Asati (rajiva) <rajiva@cisco.com> wrote:
Yes, MAP (T-Translation or E-Encap mode) is implemented on two regular routers that I know of - ASR9K and ASR1K. Without that, you are right that MAP wouldn't have been as beneficial as claimed.
glad it's cross platform... is it also IP encumbered so it'll remain just as 'cross platform' ?
Oh, it certainly is (per the IETF IPR rules). Thanks for the clarity, Chuck. Cheers, Rajiv -----Original Message----- From: Chuck Anderson <cra@WPI.EDU> Date: Monday, April 8, 2013 3:18 PM To: Rajiv Asati <rajiva@cisco.com> Cc: Christopher Morrow <morrowc.lists@gmail.com>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
I think he means patent encumbered.
On Mon, Apr 08, 2013 at 07:13:11PM +0000, Rajiv Asati (rajiva) wrote:
Chris,
UmmmŠ you mean the IPv6 and IPv4 inter-dependency when you say IP encumbered?
If so, the answer is Yes. v6 addressing doesn't need to change to accommodate this IPv4 A+P encoding.
Cheers, Rajiv
-----Original Message----- From: Christopher Morrow <morrowc.lists@gmail.com> Date: Monday, April 8, 2013 2:28 PM To: Rajiv Asati <rajiva@cisco.com> Cc: Mikael Abrahamsson <swmike@swm.pp.se>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
On Mon, Apr 8, 2013 at 2:19 PM, Rajiv Asati (rajiva) <rajiva@cisco.com> wrote:
Yes, MAP (T-Translation or E-Encap mode) is implemented on two regular routers that I know of - ASR9K and ASR1K. Without that, you are right
that
MAP wouldn't have been as beneficial as claimed.
glad it's cross platform... is it also IP encumbered so it'll remain just as 'cross platform' ?
On Mon, Apr 8, 2013 at 3:21 PM, Rajiv Asati (rajiva) <rajiva@cisco.com>wrote:
Oh, it certainly is (per the IETF IPR rules).
which rfcs? I can find a draft in softwire: http://tools.ietf.org/html/draft-mdt-softwire-map-translation-01 and a reference to this in wikipedia: http://en.wikipedia.org/wiki/IPv6_transition_mechanisms#MAP which says: "...(MAP) is a Cisco IPv6 transition proposal..." so.. err, we won't see this in juniper gear since: 1) not a standard 2) encumbered by IPR issues weee!
Thanks for the clarity, Chuck.
Cheers, Rajiv
-----Original Message----- From: Chuck Anderson <cra@WPI.EDU> Date: Monday, April 8, 2013 3:18 PM To: Rajiv Asati <rajiva@cisco.com> Cc: Christopher Morrow <morrowc.lists@gmail.com>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
I think he means patent encumbered.
On Mon, Apr 08, 2013 at 07:13:11PM +0000, Rajiv Asati (rajiva) wrote:
Chris,
UmmmŠ you mean the IPv6 and IPv4 inter-dependency when you say IP encumbered?
If so, the answer is Yes. v6 addressing doesn't need to change to accommodate this IPv4 A+P encoding.
Cheers, Rajiv
-----Original Message----- From: Christopher Morrow <morrowc.lists@gmail.com> Date: Monday, April 8, 2013 2:28 PM To: Rajiv Asati <rajiva@cisco.com> Cc: Mikael Abrahamsson <swmike@swm.pp.se>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
On Mon, Apr 8, 2013 at 2:19 PM, Rajiv Asati (rajiva) <rajiva@cisco.com> wrote:
Yes, MAP (T-Translation or E-Encap mode) is implemented on two regular routers that I know of - ASR9K and ASR1K. Without that, you are right
that
MAP wouldn't have been as beneficial as claimed.
glad it's cross platform... is it also IP encumbered so it'll remain just as 'cross platform' ?
http://datatracker.ietf.org/ipr/search/?option=document_search&id_document_tag=draft-ietf-softwire-map http://datatracker.ietf.org/doc/draft-ietf-softwire-map/?include_text=1 On Mon, Apr 08, 2013 at 03:41:54PM -0400, Christopher Morrow wrote:
On Mon, Apr 8, 2013 at 3:21 PM, Rajiv Asati (rajiva) <rajiva@cisco.com>wrote:
Oh, it certainly is (per the IETF IPR rules).
which rfcs? I can find a draft in softwire: http://tools.ietf.org/html/draft-mdt-softwire-map-translation-01
and a reference to this in wikipedia: http://en.wikipedia.org/wiki/IPv6_transition_mechanisms#MAP
which says: "...(MAP) is a Cisco IPv6 transition proposal..."
so.. err, we won't see this in juniper gear since: 1) not a standard 2) encumbered by IPR issues
weee!
Thanks for the clarity, Chuck.
Cheers, Rajiv
-----Original Message----- From: Chuck Anderson <cra@WPI.EDU> Date: Monday, April 8, 2013 3:18 PM To: Rajiv Asati <rajiva@cisco.com> Cc: Christopher Morrow <morrowc.lists@gmail.com>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
I think he means patent encumbered.
On Mon, Apr 08, 2013 at 07:13:11PM +0000, Rajiv Asati (rajiva) wrote:
Chris,
UmmmŠ you mean the IPv6 and IPv4 inter-dependency when you say IP encumbered?
If so, the answer is Yes. v6 addressing doesn't need to change to accommodate this IPv4 A+P encoding.
Cheers, Rajiv
-----Original Message----- From: Christopher Morrow <morrowc.lists@gmail.com> Date: Monday, April 8, 2013 2:28 PM To: Rajiv Asati <rajiva@cisco.com> Cc: Mikael Abrahamsson <swmike@swm.pp.se>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
On Mon, Apr 8, 2013 at 2:19 PM, Rajiv Asati (rajiva) <rajiva@cisco.com> wrote:
Yes, MAP (T-Translation or E-Encap mode) is implemented on two regular routers that I know of - ASR9K and ASR1K. Without that, you are right
that
MAP wouldn't have been as beneficial as claimed.
glad it's cross platform... is it also IP encumbered so it'll remain just as 'cross platform' ?
Chris, That's an incorrect draft pointer. Here is the correct one - http://tools.ietf.org/html/draft-ietf-softwire-map tools.ietf.org/html/draft-ietf-softwire-map-t http://tools.ietf.org/html/draft-ietf-softwire-map-dhcp And no, Cisco has no IPR on MAP wrt the above drafts. Cheers, Rajiv PS: Please do note that the IPRs mostly get nullified once they are through the IETF standards process. -----Original Message----- From: Christopher Morrow <morrowc.lists@gmail.com> Date: Monday, April 8, 2013 3:41 PM To: Rajiv Asati <rajiva@cisco.com> Cc: Chuck Anderson <cra@WPI.EDU>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
On Mon, Apr 8, 2013 at 3:21 PM, Rajiv Asati (rajiva) <rajiva@cisco.com> wrote:
Oh, it certainly is (per the IETF IPR rules).
which rfcs? I can find a draft in softwire: http://tools.ietf.org/html/draft-mdt-softwire-map-translation-01
and a reference to this in wikipedia: http://en.wikipedia.org/wiki/IPv6_transition_mechanisms#MAP
which says: "...(MAP) is a Cisco IPv6 transition proposal..."
so.. err, we won't see this in juniper gear since: 1) not a standard 2) encumbered by IPR issues
weee!
Thanks for the clarity, Chuck.
Cheers, Rajiv
-----Original Message----- From: Chuck Anderson <cra@WPI.EDU> Date: Monday, April 8, 2013 3:18 PM To: Rajiv Asati <rajiva@cisco.com>
Cc: Christopher Morrow <morrowc.lists@gmail.com>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
I think he means patent encumbered.
On Mon, Apr 08, 2013 at 07:13:11PM +0000, Rajiv Asati (rajiva) wrote:
Chris,
UmmmŠ you mean the IPv6 and IPv4 inter-dependency when you say IP encumbered?
If so, the answer is Yes. v6 addressing doesn't need to change to accommodate this IPv4 A+P encoding.
Cheers, Rajiv
-----Original Message----- From: Christopher Morrow <morrowc.lists@gmail.com> Date: Monday, April 8, 2013 2:28 PM To: Rajiv Asati <rajiva@cisco.com> Cc: Mikael Abrahamsson <swmike@swm.pp.se>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
On Mon, Apr 8, 2013 at 2:19 PM, Rajiv Asati (rajiva) <rajiva@cisco.com> wrote:
Yes, MAP (T-Translation or E-Encap mode) is implemented on two regular routers that I know of - ASR9K and ASR1K. Without that, you are right
that
MAP wouldn't have been as beneficial as claimed.
glad it's cross platform... is it also IP encumbered so it'll remain just as 'cross platform' ?
On Mon, Apr 8, 2013 at 3:48 PM, Rajiv Asati (rajiva) <rajiva@cisco.com>wrote:
Chris,
That's an incorrect draft pointer. Here is the correct one -
http://tools.ietf.org/html/draft-ietf-softwire-map tools.ietf.org/html/draft-ietf-softwire-map-t http://tools.ietf.org/html/draft-ietf-softwire-map-dhcp
great, but still a draft, not an official standard.
And no, Cisco has no IPR on MAP wrt the above drafts.
'yet'... they don't have to officially declare until WGLC... and REALLY not until the draft is sent up to the IESG, but doing it early is certainly nice so that the WG has an opportunity to say: "yea, IPR here is going to cause a problem with interop/etc".
Cheers, Rajiv
PS: Please do note that the IPRs mostly get nullified once they are through the IETF standards process.
that's not been my experience.. see flow-spec for a great example. 'mostly nullified' is .. disingenuous at best.
-----Original Message----- From: Christopher Morrow <morrowc.lists@gmail.com> Date: Monday, April 8, 2013 3:41 PM To: Rajiv Asati <rajiva@cisco.com> Cc: Chuck Anderson <cra@WPI.EDU>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
On Mon, Apr 8, 2013 at 3:21 PM, Rajiv Asati (rajiva) <rajiva@cisco.com> wrote:
Oh, it certainly is (per the IETF IPR rules).
which rfcs? I can find a draft in softwire: http://tools.ietf.org/html/draft-mdt-softwire-map-translation-01
and a reference to this in wikipedia: http://en.wikipedia.org/wiki/IPv6_transition_mechanisms#MAP
which says: "...(MAP) is a Cisco IPv6 transition proposal..."
so.. err, we won't see this in juniper gear since: 1) not a standard 2) encumbered by IPR issues
weee!
Thanks for the clarity, Chuck.
Cheers, Rajiv
-----Original Message----- From: Chuck Anderson <cra@WPI.EDU> Date: Monday, April 8, 2013 3:18 PM To: Rajiv Asati <rajiva@cisco.com>
Cc: Christopher Morrow <morrowc.lists@gmail.com>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
I think he means patent encumbered.
On Mon, Apr 08, 2013 at 07:13:11PM +0000, Rajiv Asati (rajiva) wrote:
Chris,
UmmmŠ you mean the IPv6 and IPv4 inter-dependency when you say IP encumbered?
If so, the answer is Yes. v6 addressing doesn't need to change to accommodate this IPv4 A+P encoding.
Cheers, Rajiv
-----Original Message----- From: Christopher Morrow <morrowc.lists@gmail.com> Date: Monday, April 8, 2013 2:28 PM To: Rajiv Asati <rajiva@cisco.com> Cc: Mikael Abrahamsson <swmike@swm.pp.se>, nanog list <nanog@nanog.org
Subject: Re: Verizon DSL moving to CGN
On Mon, Apr 8, 2013 at 2:19 PM, Rajiv Asati (rajiva) <rajiva@cisco.com> wrote:
Yes, MAP (T-Translation or E-Encap mode) is implemented on two regular routers that I know of - ASR9K and ASR1K. Without that, you are right
that
MAP wouldn't have been as beneficial as claimed.
glad it's cross platform... is it also IP encumbered so it'll remain just as 'cross platform' ?
Chris, Your points are well taken. Cheers, Rajiv -----Original Message----- From: Christopher Morrow <morrowc.lists@gmail.com> Date: Monday, April 8, 2013 3:57 PM To: Rajiv Asati <rajiva@cisco.com> Cc: Chuck Anderson <cra@WPI.EDU>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
On Mon, Apr 8, 2013 at 3:48 PM, Rajiv Asati (rajiva) <rajiva@cisco.com> wrote:
Chris,
That's an incorrect draft pointer. Here is the correct one -
http://tools.ietf.org/html/draft-ietf-softwire-map tools.ietf.org/html/draft-ietf-softwire-map-t <http://tools.ietf.org/html/draft-ietf-softwire-map-t> http://tools.ietf.org/html/draft-ietf-softwire-map-dhcp
great, but still a draft, not an official standard.
And no, Cisco has no IPR on MAP wrt the above drafts.
'yet'... they don't have to officially declare until WGLC... and REALLY not until the draft is sent up to the IESG, but doing it early is certainly nice so that the WG has an opportunity to say: "yea, IPR here is going to cause a problem with interop/etc".
Cheers, Rajiv
PS: Please do note that the IPRs mostly get nullified once they are through the IETF standards process.
that's not been my experience.. see flow-spec for a great example. 'mostly nullified' is .. disingenuous at best.
-----Original Message----- From: Christopher Morrow <morrowc.lists@gmail.com>
Date: Monday, April 8, 2013 3:41 PM To: Rajiv Asati <rajiva@cisco.com>
Cc: Chuck Anderson <cra@WPI.EDU>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
On Mon, Apr 8, 2013 at 3:21 PM, Rajiv Asati (rajiva) <rajiva@cisco.com> wrote:
Oh, it certainly is (per the IETF IPR rules).
which rfcs? I can find a draft in softwire:
http://tools.ietf.org/html/draft-mdt-softwire-map-translation-01 <http://tools.ietf.org/html/draft-mdt-softwire-map-translation-01>
and a reference to this in wikipedia: http://en.wikipedia.org/wiki/IPv6_transition_mechanisms#MAP
which says: "...(MAP) is a Cisco IPv6 transition proposal..."
so.. err, we won't see this in juniper gear since: 1) not a standard 2) encumbered by IPR issues
weee!
Thanks for the clarity, Chuck.
Cheers, Rajiv
-----Original Message----- From: Chuck Anderson <cra@WPI.EDU> Date: Monday, April 8, 2013 3:18 PM To: Rajiv Asati <rajiva@cisco.com>
Cc: Christopher Morrow <morrowc.lists@gmail.com>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
I think he means patent encumbered.
On Mon, Apr 08, 2013 at 07:13:11PM +0000, Rajiv Asati (rajiva) wrote:
Chris,
UmmmŠ you mean the IPv6 and IPv4 inter-dependency when you say IP encumbered?
If so, the answer is Yes. v6 addressing doesn't need to change to accommodate this IPv4 A+P encoding.
Cheers, Rajiv
-----Original Message----- From: Christopher Morrow <morrowc.lists@gmail.com> Date: Monday, April 8, 2013 2:28 PM To: Rajiv Asati <rajiva@cisco.com> Cc: Mikael Abrahamsson <swmike@swm.pp.se>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
On Mon, Apr 8, 2013 at 2:19 PM, Rajiv Asati (rajiva) <rajiva@cisco.com> wrote:
Yes, MAP (T-Translation or E-Encap mode) is implemented on two
routers that I know of - ASR9K and ASR1K. Without that, you are right
regular that
MAP wouldn't have been as beneficial as claimed.
glad it's cross platform... is it also IP encumbered so it'll remain just as 'cross platform' ?

In what sense do you mean that? The end-user IPv6 prefix certainly ties IPv4 and IPv6 together, hence the interest in the Light-Weight IPv4 over IPv6 alternative. Tom On 08/04/2013 3:13 PM, Rajiv Asati (rajiva) wrote:
Chris,
UmmmŠ you mean the IPv6 and IPv4 inter-dependency when you say IP encumbered?
If so, the answer is Yes. v6 addressing doesn't need to change to accommodate this IPv4 A+P encoding.
Cheers, Rajiv
...
Hi Tom, Good question. The End-user IPv6 prefix can be constructed using whatever techniques independent of MAP etc. in any deployment requiring IPv4 address sharing. What is interesting is that the MAP enabled CPE could parse certain bits of that IPv6 prefix to mean something for MAP. That's it. Attached is a screenshot to illustrate this very point. Cheers, Rajiv -----Original Message----- From: Tom Taylor <tom.taylor.stds@gmail.com> Date: Monday, April 8, 2013 3:48 PM To: "nanog@nanog.org" <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
In what sense do you mean that? The end-user IPv6 prefix certainly ties IPv4 and IPv6 together, hence the interest in the Light-Weight IPv4 over IPv6 alternative.
Tom
On 08/04/2013 3:13 PM, Rajiv Asati (rajiva) wrote:
Chris,
UmmmŠ you mean the IPv6 and IPv4 inter-dependency when you say IP encumbered?
If so, the answer is Yes. v6 addressing doesn't need to change to accommodate this IPv4 A+P encoding.
Cheers, Rajiv
...
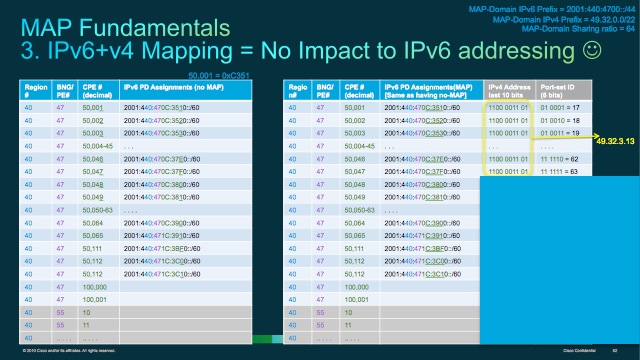{kind=link}
I think what that screenshot is saying is that after you deploy MAP, then if you stop using it the IPv6 addresses don't need to change. I would assume you're not saying that you can take your IPv6 addresses as you find them and interpret them as MAP End-user prefixes. Tom On 08/04/2013 5:38 PM, Rajiv Asati (rajiva) wrote:
Hi Tom,
Good question.
The End-user IPv6 prefix can be constructed using whatever techniques independent of MAP etc. in any deployment requiring IPv4 address sharing.
What is interesting is that the MAP enabled CPE could parse certain bits of that IPv6 prefix to mean something for MAP. That's it. Attached is a screenshot to illustrate this very point.
Cheers, Rajiv
-----Original Message----- From: Tom Taylor <tom.taylor.stds@gmail.com> Date: Monday, April 8, 2013 3:48 PM To: "nanog@nanog.org" <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
In what sense do you mean that? The end-user IPv6 prefix certainly ties IPv4 and IPv6 together, hence the interest in the Light-Weight IPv4 over IPv6 alternative.
Tom
On 08/04/2013 3:13 PM, Rajiv Asati (rajiva) wrote:
Chris,
UmmmŠ you mean the IPv6 and IPv4 inter-dependency when you say IP encumbered?
If so, the answer is Yes. v6 addressing doesn't need to change to accommodate this IPv4 A+P encoding.
Cheers, Rajiv
...
Hi Tom, The key take-away is that MAP doesn't _necessarily_ require IPv6 prefix to be constructed in a special way (so as to encode the IPv4 address inside it). Please see more inline,
I think what that screenshot is saying is that after you deploy MAP, then if you stop using it the IPv6 addresses don't need to change.
Yes.
I would assume you're not saying that you can take your IPv6 addresses as you find them and interpret them as MAP End-user prefixes.
It can work even in that realm as well (IPv6 PD assumed). There are pros & cons of doing this, suffice to say. Cheers, Rajiv -----Original Message----- From: Tom Taylor <tom.taylor.stds@gmail.com> Date: Monday, April 8, 2013 8:51 PM To: Rajiv Asati <rajiva@cisco.com> Cc: "nanog@nanog.org" <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
I think what that screenshot is saying is that after you deploy MAP, then if you stop using it the IPv6 addresses don't need to change. I would assume you're not saying that you can take your IPv6 addresses as you find them and interpret them as MAP End-user prefixes.
Tom
On 08/04/2013 5:38 PM, Rajiv Asati (rajiva) wrote:
Hi Tom,
Good question.
The End-user IPv6 prefix can be constructed using whatever techniques independent of MAP etc. in any deployment requiring IPv4 address sharing.
What is interesting is that the MAP enabled CPE could parse certain bits of that IPv6 prefix to mean something for MAP. That's it. Attached is a screenshot to illustrate this very point.
Cheers, Rajiv
-----Original Message----- From: Tom Taylor <tom.taylor.stds@gmail.com> Date: Monday, April 8, 2013 3:48 PM To: "nanog@nanog.org" <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
In what sense do you mean that? The end-user IPv6 prefix certainly ties IPv4 and IPv6 together, hence the interest in the Light-Weight IPv4 over IPv6 alternative.
Tom
On 08/04/2013 3:13 PM, Rajiv Asati (rajiva) wrote:
Chris,
UmmmŠ you mean the IPv6 and IPv4 inter-dependency when you say IP encumbered?
If so, the answer is Yes. v6 addressing doesn't need to change to accommodate this IPv4 A+P encoding.
Cheers, Rajiv
...
Dual-stack in the home networks will stay with us for a long time (beyond 2020!) until v4-only user devices and v4-only apps get refreshed. Of course, this doesn't mean that the ISP access needs to stay dual-stack, thanks to MAP, 464XLAT etc. Cheers, Rajiv Sent from my Phone On Apr 7, 2013, at 3:15 AM, "Fabien Delmotte" <fdelmotte1@mac.com> wrote:
CGN is just a solution to save time, it is not a transition mechanism through IPv6 At the end (IPv6 at home) you will need at list : Dual stack or NAT64/ DNS64
My 2 cents
On Apr 7, 2013, at 8:42 AM, Mikael Abrahamsson <swmike@swm.pp.se> wrote:
On Sun, 7 Apr 2013, Christopher Morrow wrote:
I wonder how much more painful just upgrading the dsl plant to support v6 would be vs deploying the cgn equipment and funneling users through that :(
IPv6 deployment is not a short term solution to IPv4 address depletion. Would you be less upset if there was IPv6 access and CPE based DS Lite (ie your IPv4 is still CGN:ed, just in a different way)?
CGN is here to stay for IPv4. The solution for long term Internet growth is IPv6.
-- Mikael Abrahamsson email: swmike@swm.pp.se
On Apr 7, 2013, at 18:21 , Rajiv Asati (rajiva) <rajiva@cisco.com> wrote:
Dual-stack in the home networks will stay with us for a long time (beyond 2020!) until v4-only user devices and v4-only apps get refreshed.
I disagree. I think that v4-only apps and devices will get relegated to being connected through v4-v6 adapter appliances until they are fixed. IPv4 is simply going to become far too expensive to maintain to be able to deliver it for residential pricing.
Of course, this doesn't mean that the ISP access needs to stay dual-stack, thanks to MAP, 464XLAT etc.
Right... Those are some of the ways that maintaining IPv4 will become so expensive. ;-) Owen
Like you, I would like to be optimistic about many v4-only apps and v4-only devices becoming dual-stack sooner than later. But knowing that a significant (50%+) of android devices may not support IPv6 (just like my brand new Samsung Galaxy 7'' tablet (just bought over the weekend) being v4-only) and may not be upgraded by their users to the right software, and that Skype etc. apps are out there, my optimism fades away. Cheers, Rajiv -----Original Message----- From: Owen DeLong <owen@delong.com> Date: Monday, April 8, 2013 1:38 AM To: Rajiv Asati <rajiva@cisco.com> Cc: Fabien Delmotte <fdelmotte1@mac.com>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
On Apr 7, 2013, at 18:21 , Rajiv Asati (rajiva) <rajiva@cisco.com> wrote:
Dual-stack in the home networks will stay with us for a long time (beyond 2020!) until v4-only user devices and v4-only apps get refreshed.
I disagree. I think that v4-only apps and devices will get relegated to being connected through v4-v6 adapter appliances until they are fixed.
IPv4 is simply going to become far too expensive to maintain to be able to deliver it for residential pricing.
Of course, this doesn't mean that the ISP access needs to stay dual-stack, thanks to MAP, 464XLAT etc.
Right... Those are some of the ways that maintaining IPv4 will become so expensive. ;-)
Owen

Once upon a time, Rajiv Asati (rajiva) <rajiva@cisco.com> said:
But knowing that a significant (50%+) of android devices may not support IPv6 (just like my brand new Samsung Galaxy 7'' tablet (just bought over the weekend) being v4-only) and may not be upgraded by their users to the right software, and that Skype etc. apps are out there, my optimism fades away.
Yeah, Samsung is screwy on Android+IPv6. My (less than 6 month old) Samsung phone with Android 4.0 gets an IPv6 address (autoconfigured) but does not add an IPv6 default route, so it can't reach the IPv6 Internet over wi-fi. IIRC when I enabled T-Mobile's IPv6 APN, it did handle IPv6 over the cell network okay. My generic Chinese import Android 4.0 tablet works just fine with IPv6, as did my old HTC/T-Mobile G2 (wi-fi only). -- Chris Adams <cmadams@hiwaay.net> Systems and Network Administrator - HiWAAY Internet Services I don't speak for anybody but myself - that's enough trouble.
On Apr 8, 2013, at 11:54 , Rajiv Asati (rajiva) <rajiva@cisco.com> wrote:
Like you, I would like to be optimistic about many v4-only apps and v4-only devices becoming dual-stack sooner than later.
But knowing that a significant (50%+) of android devices may not support IPv6 (just like my brand new Samsung Galaxy 7'' tablet (just bought over the weekend) being v4-only) and may not be upgraded by their users to the right software, and that Skype etc. apps are out there, my optimism fades away.
The upgrade problem isn't that hard to solve. As soon as users want to use something that doesn't work without the upgrade, the upgrades get installed. Apple does a great job of this... Every time they release an iOS upgrade I really don't want, they manage to also release an update to software that I do care about. That software update inherently requires me to accept the iOS upgrade. Owen
I agree. Apple does it really well, no doubt about it. This is because they control both the software and hardware. Google/Android çan not do it well enough, since the Android OS version compatibility with the hardware is somewhat dictated by the hardware manufacturer. This isn't always helpful. :-( For ex, there are numerous android apps that are not supported on many android devices. :=( Anyway, this is why I think that dual-stack home networks (and UEs) will be with us for a long time. Cheers, Rajiv -----Original Message----- From: Owen DeLong <owen@delong.com> Date: Monday, April 8, 2013 8:52 PM To: Rajiv Asati <rajiva@cisco.com> Cc: Fabien Delmotte <fdelmotte1@mac.com>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
On Apr 8, 2013, at 11:54 , Rajiv Asati (rajiva) <rajiva@cisco.com> wrote:
Like you, I would like to be optimistic about many v4-only apps and v4-only devices becoming dual-stack sooner than later.
But knowing that a significant (50%+) of android devices may not support IPv6 (just like my brand new Samsung Galaxy 7'' tablet (just bought over the weekend) being v4-only) and may not be upgraded by their users to the right software, and that Skype etc. apps are out there, my optimism fades away.
The upgrade problem isn't that hard to solve. As soon as users want to use something that doesn't work without the upgrade, the upgrades get installed.
Apple does a great job of this...
Every time they release an iOS upgrade I really don't want, they manage to also release an update to software that I do care about. That software update inherently requires me to accept the iOS upgrade.
Owen
On Apr 8, 2013, at 20:23 , "Rajiv Asati (rajiva)" <rajiva@cisco.com> wrote:
I agree. Apple does it really well, no doubt about it. This is because they control both the software and hardware.
Google/Android çan not do it well enough, since the Android OS version compatibility with the hardware is somewhat dictated by the hardware manufacturer. This isn't always helpful. :-(
But they can actually push pretty well if they had some killer app. that everyone used and could supply some update that nobody could live without on said killer app. Then you just need to flag said update as "requires Android version X" and poof... All the pressure you need to get everyone running droid up to X. (Including all the pressure needed to get consumers to push the device maker.)
For ex, there are numerous android apps that are not supported on many android devices. :=(
They must not be very important to the bulk of the android users.
Anyway, this is why I think that dual-stack home networks (and UEs) will be with us for a long time.
I don't doubt that dual-stack home networks will be with us for a long time. What won't be with us for very long is routing IPv4 across service providers. It can't. It will become far too expensive to do so. The economics aren't going to work much past about 5 years, maybe 10 if we're really unlucky. Owen
Cheers, Rajiv
-----Original Message----- From: Owen DeLong <owen@delong.com> Date: Monday, April 8, 2013 8:52 PM To: Rajiv Asati <rajiva@cisco.com> Cc: Fabien Delmotte <fdelmotte1@mac.com>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
On Apr 8, 2013, at 11:54 , Rajiv Asati (rajiva) <rajiva@cisco.com> wrote:
Like you, I would like to be optimistic about many v4-only apps and v4-only devices becoming dual-stack sooner than later.
But knowing that a significant (50%+) of android devices may not support IPv6 (just like my brand new Samsung Galaxy 7'' tablet (just bought over the weekend) being v4-only) and may not be upgraded by their users to the right software, and that Skype etc. apps are out there, my optimism fades away.
The upgrade problem isn't that hard to solve. As soon as users want to use something that doesn't work without the upgrade, the upgrades get installed.
Apple does a great job of this...
Every time they release an iOS upgrade I really don't want, they manage to also release an update to software that I do care about. That software update inherently requires me to accept the iOS upgrade.
Owen
I don't doubt that dual-stack home networks will be with us for a long time. What won't be with us for very long is routing IPv4 across service providers. It can't. It will become far too expensive to do so. The economics aren't going to work much past about 5 years, maybe 10 if we're really unlucky.
Of course. :) Cheers, Rajiv -----Original Message----- From: Owen DeLong <owen@delong.com> Date: Tuesday, April 9, 2013 12:01 AM To: Rajiv Asati <rajiva@cisco.com> Cc: Fabien Delmotte <fdelmotte1@mac.com>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
On Apr 8, 2013, at 20:23 , "Rajiv Asati (rajiva)" <rajiva@cisco.com> wrote:
I agree. Apple does it really well, no doubt about it. This is because they control both the software and hardware.
Google/Android çan not do it well enough, since the Android OS version compatibility with the hardware is somewhat dictated by the hardware manufacturer. This isn't always helpful. :-(
But they can actually push pretty well if they had some killer app. that everyone used and could supply some update that nobody could live without on said killer app.
Then you just need to flag said update as "requires Android version X" and poof... All the pressure you need to get everyone running droid up to X. (Including all the pressure needed to get consumers to push the device maker.)
For ex, there are numerous android apps that are not supported on many android devices. :=(
They must not be very important to the bulk of the android users.
Anyway, this is why I think that dual-stack home networks (and UEs) will be with us for a long time.
I don't doubt that dual-stack home networks will be with us for a long time. What won't be with us for very long is routing IPv4 across service providers. It can't. It will become far too expensive to do so. The economics aren't going to work much past about 5 years, maybe 10 if we're really unlucky.
Owen
Cheers, Rajiv
-----Original Message----- From: Owen DeLong <owen@delong.com> Date: Monday, April 8, 2013 8:52 PM To: Rajiv Asati <rajiva@cisco.com> Cc: Fabien Delmotte <fdelmotte1@mac.com>, nanog list <nanog@nanog.org> Subject: Re: Verizon DSL moving to CGN
On Apr 8, 2013, at 11:54 , Rajiv Asati (rajiva) <rajiva@cisco.com> wrote:
Like you, I would like to be optimistic about many v4-only apps and v4-only devices becoming dual-stack sooner than later.
But knowing that a significant (50%+) of android devices may not support IPv6 (just like my brand new Samsung Galaxy 7'' tablet (just bought over the weekend) being v4-only) and may not be upgraded by their users to the right software, and that Skype etc. apps are out there, my optimism fades away.
The upgrade problem isn't that hard to solve. As soon as users want to use something that doesn't work without the upgrade, the upgrades get installed.
Apple does a great job of this...
Every time they release an iOS upgrade I really don't want, they manage to also release an update to software that I do care about. That software update inherently requires me to accept the iOS upgrade.
Owen
In all fairness, upgrading the legacy last-mile e.g. DSL infrastructure to support native IPv6 may be too expensive to make any economic sense. Note that Vz FiOS users are not affected by this. And noting that Vz has ~5.5M FiOS HSI customers and ~3M DSL customers (per the last earning report), and noting that DSL network is not getting any new investment (in fact, customers are being moved from DSL to FiOS), the CGN usage for DSL customers isn't quite surprising. http://stopthecap.com/2012/08/20/verizon-declares-copper-dead-quietly-moving... Many ISPs around the world are choosing to not to invest in the DSL network the way they used to. Cheers, Rajiv Sent from my Phone On Apr 6, 2013, at 10:13 PM, "Constantine A. Murenin" <mureninc@gmail.com<mailto:mureninc@gmail.com>> wrote: On 6 April 2013 18:24, cb.list6 <cb.list6@gmail.com<mailto:cb.list6@gmail.com>> wrote: Interesting. http://www22.verizon.com/support/residential/internet/highspeedinternet/netw... <blockquote> What is CGN - and How to opt-out The number and types of devices using the Internet have increased dramatically in recent years and, as a result, address space for these devices is being rapidly exhausted. Today’s technology for IP addresses is referred to as IPv4 (Internet Protocol version 4). The IP addresses aligned with IPv4 are expected to be depleted at some point in the near future. The next generation of IP address space is IPv6, which will enable far more addresses to be assigned than IPv4. Unfortunately, most servers and other Internet devices will not be speaking IPv6 for a while, so IPv4 will remain standard for some time to come. During this transitional period, in select areas for High Speed Internet residential customers, Verizon will be implementing Carrier Grade Network Address Translation (CGN or Carrier Grade NAT). Verizon FiOS and Verizon Business customers are not impacted at this time by the change. This transition will enable Verizon to continue serving customers with IPv4 internet addresses. CGN will not impact the access, reliability, speed, or security of Verizon’s broadband services. However, there are some applications such as online gaming, VPN access, FTP service, surveillance cameras, etc., that may not work when broadband service is provided via a CGN. For our customers utilizing these types of applications, Verizon provides the ability to "opt out “of CGN. To "opt out" you must: Be a Residential customer with High Speed Internet Service. There is no need to “opt-out” if you are a FiOS or Business customer. Have already been transitioned to the Carrier Grade Network by Verizon. If you are a Residential High Speed Internet customer and are unable to opt-out, it is likely that you have not yet been transitioned to CGN. To "opt out" of CGN sign onto your My Verizon account and select "Opt out of Carrier Grade Network". </blockquote> I like how, according to the document, Verizon must first break your connectivity, prior to you being able to opt-out. :-) Also: select "Opt out of Carrier Grade Network" Smart wording. :-) Frankly, I'm surprised to see this news. I thought Verizon had better things to do that plan any kind of upgrades or changes to something that everyone thought they consider dead anyways. C.
----- Original Message -----
From: "Rajiv Asati (rajiva)" <rajiva@cisco.com>
Note that Vz FiOS users are not affected by this. And noting that Vz has ~5.5M FiOS HSI customers and ~3M DSL customers (per the last earning report), and noting that DSL network is not getting any new investment (in fact, customers are being moved from DSL to FiOS), the CGN usage for DSL customers isn't quite surprising.
http://stopthecap.com/2012/08/20/verizon-declares-copper-dead-quietly-moving...
Well, that's as may be, but since Vzn has also declared *on the record, at least 2 years ago* that they're done with FiOS -- they ain't building no more of it, if you don't have it, sorry for your luck (except maybe in KC and Austin) -- I don't know if that helps them any. Cheers, -- jra -- Jay R. Ashworth Baylink jra@baylink.com Designer The Things I Think RFC 2100 Ashworth & Associates http://baylink.pitas.com 2000 Land Rover DII St Petersburg FL USA #natog +1 727 647 1274

On 4/6/2013 6:24 PM, cb.list6 wrote:
Interesting.
http://www22.verizon.com/support/residential/internet/highspeedinternet/netw...
I'd love to see a CGN box that is cheaper than IPv4 addresses currently are on the transfer market. Matthew Kaufman
On Sat, 6 Apr 2013, Matthew Kaufman wrote:
I'd love to see a CGN box that is cheaper than IPv4 addresses currently are on the transfer market.
That depends on what you think the prices are for IPv4 addresses and what you think the prices are for CGN boxes. At the prices I'm hearing, it's cheaper to CGN 50k users (or more) than to purchase IPv4 addresses. Otoh, ARIN isn't exhausted yet so getting IPv4 addresses there should still be a lot cheaper than doing CGN? -- Mikael Abrahamsson email: swmike@swm.pp.se
* Mikael Abrahamsson
Otoh, ARIN isn't exhausted yet so getting IPv4 addresses there should still be a lot cheaper than doing CGN?
From what I hear several ISPs in the ARIN region prefer to obtain second-hand IPv4 addresses (or deploy CGN boxes) over requesting addresses directly from ARIN, and the reason is that ARIN, per policy, will only give its members addresses to cover three months' worth of consumption, and that this period is simply too short for the allocation to be operationally useful, especially for large organisations.
I have an anecdote to share here: A while back, a techie from a large organisation in the RIPE region told me that from their point of view, the RIPE NCC was effectively depleted once they implemented the three-month period for allocations on the 1st of July 2011, because they needed more than three months to actually put a new allocation in production - hence they couldn't justify anything any longer. When transferring, on the other hand, ARIN's policies allows for obtaining up to 24 months' worth of space. This gives longer-term operational predictability, which may easily justify the cost of the addresses themselves. Same thing goes for deploying CGNs instead - the organisation is then free to plan as far ahead as it feels like, without being constrained by ARIN policies. That has a value, possibly more than the cost of the CGN boxes themselves. Tore

On 4/6/13, Matthew Kaufman <matthew@matthew.at> wrote:
On 4/6/2013 6:24 PM, cb.list6 wrote:
I'd love to see a CGN box that is cheaper than IPv4 addresses currently are on the transfer market.
You mean like a few linux servers running iptables nat-masquerade? You think the "Carrier Grade" in "Carrier Grade NAT" isn't just a rhetorically constructed distraction, from the fact that simple NAT may be implemented, and yeah, end users are certain to experience annoyances, either way...
Matthew Kaufman
-- -JH
Jimmy Hess <mysidia@gmail.com> writes:
On 4/6/13, Matthew Kaufman <matthew@matthew.at> wrote:
On 4/6/2013 6:24 PM, cb.list6 wrote:
I'd love to see a CGN box that is cheaper than IPv4 addresses currently are on the transfer market.
You mean like a few linux servers running iptables nat-masquerade?
You think the "Carrier Grade" in "Carrier Grade NAT" isn't just a rhetorically constructed distraction, from the fact that simple NAT may be implemented, and yeah, end users are certain to experience annoyances, either way...
Forget about the "annoying users" part; the "carrier-grade" part of CGN is all about not annoying the service provider. As far as I'm aware, iptables does not include deterministic port translation based on source address, nor easy-to-configure hooks for CALEA [*]. It may well turn out that once one factors in support your costs are higher with large scale NAT-on-Linux than if you'd sucked it up and coughed up a quarter mil for an appliance. -r [*] I'd love to hear that I'm wrong on this count, but a how-to document that explains how one can lovingly handcraft such a thing as opposed to a special refactored distro that's ready to plug-and-chug appliance style will only serve to reinforce my assertion.
----- Original Message -----
From: "cb.list6" <cb.list6@gmail.com>
Interesting.
http://www22.verizon.com/support/residential/internet/highspeedinternet/netw... What I find amusing is how they call it "Carrier Grade NAT" one time, and then switch to calling it "Carrier Grade Network", thereby making it sound all cool and better and stuff... Cheers, -- jra -- Jay R. Ashworth Baylink jra@baylink.com Designer The Things I Think RFC 2100 Ashworth & Associates http://baylink.pitas.com 2000 Land Rover DII St Petersburg FL USA #natog +1 727 647 1274

Well if the RFCs would just be set in stone already like Moses's 10 commandments and if the programmers would actually start writing code for v6 and if the web site hosting servers would at least have dual stack enabled on them it would be great. But till then we just change a RFC here, band-aid IPv4 there and wait till everything reaches critical mass and comes crashing on our heads. On 4/7/2013 5:38 AM, Jay Ashworth wrote:
----- Original Message -----
From: "cb.list6" <cb.list6@gmail.com> Interesting.
http://www22.verizon.com/support/residential/internet/highspeedinternet/netw...
What I find amusing is how they call it "Carrier Grade NAT" one time, and then switch to calling it "Carrier Grade Network", thereby making it sound all cool and better and stuff...
Cheers, -- jra
On Sun, 07 Apr 2013 13:54:04 +0300, Alex said:
Well if the RFCs would just be set in stone already like Moses's 10 commandments and if the programmers would actually start writing code for v6 and if the web site hosting servers would at least have dual stack enabled on them it would be great.
But till then we just change a RFC here, band-aid IPv4 there and wait till everything reaches critical mass and comes crashing on our heads.
I find it interesting that you complain about a 15 year old protocol not being set in stone, and cite that as a reason for no code getting done. But the solution is to take advantage of the fact that the 30 year old predecessor isn't set in stone either... (And there's no reason that programmers can't be writing code - RFC3542 came out in May 2003)

Can anyone from Verizon comment on what IP space that's being used for this? Or perhaps what the rDNS mask will look like?
From an abuse perspective, knowing that an IP is being used for this can make the difference between traffic looking like abuse and traffic looking like multiple legitimate users.
Malcolm Staudinger Information Security Analyst | EIS EarthLink -----Original Message----- From: cb.list6 [mailto:cb.list6@gmail.com] Sent: Saturday, April 06, 2013 6:24 PM To: nanog@nanog.org Subject: Verizon DSL moving to CGN Interesting. http://www22.verizon.com/support/residential/internet/highspeedinternet/ networking/troubleshooting/portforwarding/123897.htm
participants (37)
-
 Alex
Alex -
 Arturo Servin
Arturo Servin -
 Brzozowski, John
Brzozowski, John -
 cb.list6
cb.list6 -
 Chris Adams
Chris Adams -
 Christopher Morrow
Christopher Morrow -
 Chuck Anderson
Chuck Anderson -
 Constantine A. Murenin
Constantine A. Murenin -
 Derek Ivey
Derek Ivey -
 Fabien Delmotte
Fabien Delmotte -
 Huasong Zhou
Huasong Zhou -
 Jack Bates
Jack Bates -
 Jay Ashworth
Jay Ashworth -
 Jimmy Hess
Jimmy Hess -
 joel jaeggli
joel jaeggli -
 Joshua Smith
Joshua Smith -
 Julien Goodwin
Julien Goodwin -
 Justin M. Streiner
Justin M. Streiner -
 Leo Bicknell
Leo Bicknell -
 Livingood, Jason
Livingood, Jason -
 Matthew Kaufman
Matthew Kaufman -
 Mikael Abrahamsson
Mikael Abrahamsson -
 Oliver Garraux
Oliver Garraux -
 Owen DeLong
Owen DeLong -
 Rajiv Asati (rajiva)
Rajiv Asati (rajiva) -
 Randy Bush
Randy Bush -
 Rob Seastrom
Rob Seastrom -
 Sam Hayes Merritt, III
Sam Hayes Merritt, III -
 Seth Mattinen
Seth Mattinen -
 Seth Mos
Seth Mos -
 Shishio Tsuchiya
Shishio Tsuchiya -
 Simon Lockhart
Simon Lockhart -
 Staudinger, Malcolm
Staudinger, Malcolm -
 Tom Taylor
Tom Taylor -
 Tore Anderson
Tore Anderson -
 Valdis.Kletnieks@vt.edu
Valdis.Kletnieks@vt.edu -
 William Warren
William Warren